并发的概念
并发(concurrency)与并行(parallel)的含义在很大程度上重叠,差别甚小。但是并行更强调性能,并发更关心的是分离关注点
多线程并发与多进程并发
为什么使用并发:
- 为分离关注点(separation of concerns)而并发
- 为性能而并发:
- 任务并行:分解任务
- 数据并行:线程分别对数据的不同部分执行相同操作
线程管控
发起线程
使用 std::thread,可以传入一个可调用对象和它的构造参数
注意避免 Most Vexing Parse,可以使用:
- 多加一对括号
- 使用列表初始化方法
在发起线程后,需要决定是等待(join)还是让它独自运行(detach)
如果在 std::thread 析构的时候还没决定好,那么会直接调用 std::terminate 终止整个程序
C++ 的标准库是这样写的:
~thread() {
if (joinable()) std::__terminate();
}
其中,joinable() 表示它能够进行汇合
传入参数
如果传入了构造参数,那么会使用这些参数来进行构造
注意,函数将会在新线程中执行,下面这样可能会引起某些问题:
void f(int i, const std::string& s);
void oops(int some_param) {
char buffer[1024];
std::thread t(f, 3, buffer);
t.detach();
}
上面的代码中,有可能在函数退出后才执行 std::string 的构造函数,我们提前在主线程进行构造:
std::thread t(f, 3, std::string(buffer));
上面新构造的 std::string 是一个临时对象,它是个右值,而 const T& 既可以绑定左值也可以绑定右值
如果换成 void f(int i, std::string& s); 上面的代码就编译不过了,这里和普通的函数调用不太一样:
void f(int i, std::string& s);
std::string s;
f(3, s); // 可以编译成功
std::thread t(f, 3, s); // 编译失败
这是因为在模板元编程中,大多数使用值传递,标准库也是如此(另一个例子是 std::bind),并且使用右值引用,源代码大概是这样:
template<typename _Callable, typename... _Args, typename = _Require<__not_same<_Callable>>>
explicit thread(_Callable&& __f, _Args&&... __args) {
static_assert( __is_invocable<typename decay<_Callable>::type, typename decay<_Args>::type...>::value,
"std::thread arguments must be invocable after conversion to rvalues");
...
}
Tips:如果一个复合类型有多种类型的引用,如果有 & 那就是左值引用,否则就是右值引用,这被叫做引用折叠规则,如:
std::string && && & && & & & && rs1; // 左值引用
std::string && & && && && & & rs2; // 左值引用
std::string & & && && && && && rs2; // 左值引用
std::string && && && && && && rs2; // 右值引用
它认为 f(int&&, std::string&&) 并不可调用,这非常正确,因为非 const 左值引用不能接受右值引用实参
我们可以使用 std::ref 来传递引用,这个东西实际上就是里面存了一个指针,然后定义了一个到左值引用的转换函数,源码如下:
template<typename _Tp>
class reference_wrapper {
_Tp* _M_data;
...
_Tp& get() const noexcept { return *_M_data; }
operator _Tp&() const noexcept { return this->get(); }
...
};
std::ref 可以隐式转换成所存储的对象的左值引用,如果将它作为参数,就会隐式转换成左值引用:
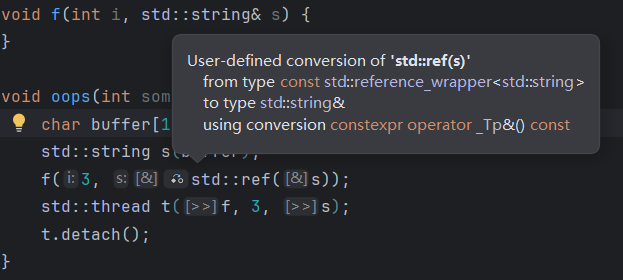
代码改成下面这样:
void f(int i, std::string& s);
std::string s;
std::thread t(f, 3, std::ref(s));
但是这样的话传递的是 s 的引用,与我们的目标不同
我们可以自己写一个可调用的的类,或者使用 lambda 表达式来完成
使用智能指针
可以使用智能指针来方便地实现线程间的引用,例如 std::unique_ptr:
void process_big_object(std::unique_ptr<big_object>);
std::unique_ptr<big_object> p(new big_object);
std::thread t(process_big_object, std::move(p));
std::unique_ptr 实现了移动构造函数,传给它右值引用它能够直接移动
等待线程完成
使用 join() 来阻塞本线程,等待子线程完成,非常简单粗暴
然而,如果想要更细粒度的线程等待,需要条件变量和 std::future
join() 只能调用一次,调用后线程就不再可汇合(joinable),joinable() 会返回 false
注意异常可能会跳过 join() 的调用,需要进行异常处理,如:
std::thread t(func);
try {
// 可能抛出异常
} catch(...) {
t.join();
throw;
}
t.join();
但是上面的处理太复杂了,在现代 C++ 中最好使用 RAII(Resource Acquisition Is Initialization,资源获取即初始化)的方式来处理,如:
class thread_gaurd {
public:
explicit thread_guard(std::thread& t) noexcept : t_(t) {
}
~thread_guard() {
if (t.joinable()) t.join();
}
thread_guard(const thread_guard&) = delete; // 其实 std::thread 根本不可拷贝
thread_guard& operator=(const thread_guard&) = delete;
private:
std::thread& t_;
};
...
std::thread t(func);
thread_gaurd g(t);
// 做一些事情
在后台运行线程
调用 detach 后,线程会在后台运行
它的归属权和控制权会转移给 C++ 运行时库(runtime library),由此保证资源的正确回收
常常被称为守护进程(daemon process)
移交线程归属权
std::thread 支持移动语义,这样它就可以转移所有权了
我们可以改进一下原来的 thread_gaurd,改成移动构造函数,这就是 std::jthread(C++ 20)做的事情
如果容器支持移动语义,那么它就可以装载 std::thread 对象,如:
void do_work(int);
void f() {
std::vector<std::thread> threads;
for (int i = 0; i < 20; ++i) {
threads.emplace_back(do_work, i);
}
for (auto& entry : threads) entry.join();
}
线程数量与线程 ID
std::thread::hardware_concurrency() 函数可以返回程序在运行中可真正并发的线程数量,如果无效返回 0
std::thread 中有个 get_id() 方法可以获取线程的 ID(std::thread::id)
或者直接调用 std::this_thread::get_id() 返回当前线程的 ID,如果没有的话返回 0
在线程间共享数据
条件竞争(Race Condition)
不变量(invariant):针对某一特定数据的断言,如“这个变量的值是链表节点的前驱”
数据更新往往会破坏不变量,如在删除节点的过程中,上面举的不变量的例子失效
条件竞争指的是在并发运行时,结果取决于各个线程执行的相对次序
很多情况下条件竞争是良性的(例如插入列表的顺序通常不重要),我们要防止恶性的条件竞争
数据竞争(data race):并发改动单个对象导致的特定的条件竞争
防止恶性条件竞争的方法:
- 采取保护措施包装数据结构
- 修改数据结构的设计及其不变量,由一连串不可拆分的改动完成数据变更,每个改动都维持不变量不被破坏。即无锁编程,通常很难正确编写
- 事务(transaction),这本书不会涵盖这个议题
最基本的方式是互斥(mutual exclusion,mutex)
用互斥保护共享数据
C++ 中 std::mutex 是互斥,使用 lock() 方法加锁,unlock() 解锁
但是现代 C++ 中通常使用 RAII 的方式,如 std::lock_guard<> 来使用互斥,它会自动加锁解锁
线程安全的容器
top() 与 pop() 引起的很隐蔽的条件竞争:
const auto value = s.top(); // 1
s.pop(); // 2
如果有两个线程,它们按照 1.1、2.1、1.2、2.2 的顺序执行,那么它们取到了同一个 top(),并且 pop() 了两次
要解决这个问题,需要从根本上更改接口设计,其中一种做法是把它们组成一个成员函数,再采取互斥保护。但是如果在拷贝时出现异常,会出现数据丢失的情况。还有一些其他方法:
- 传入引用:
pop(Item&),先进行拷贝然后再pop()。有一些问题,例如Item不一定是可赋值的 - 提供
noexcept的拷贝构造函数或移动构造函数。容器的用途很受限 - 返回指针,指向弹出的元素。可以使用智能指针如
std::shared_ptr,先把top()放到智能指针中,然后再pop()
我们可以结合上面的方法
防范死锁
C++ 提供了 std::lock() 用来同时锁住多个互斥:
class X {
private:
some_big_object some_detail;
std::mutex m;
public:
friend void swap(X& lhs, X& rhs) {
if (&lhs == &rhs) return; // 防止对同一个对象锁两次
std::lock(lhs.m, rhs.m); // 同时锁住两个互斥
std::lock_guard lock_a(lhs.m, std::adopt_lock); // 接收锁的归属权
std::lock_guard lock_b(rhs.m, std::adopt_lock);
swap(lhs.some_detail, rhs.some_detail);
}
};
其中,std::lock_guard 提供了参数 std::adopt_lock,这表示从一个已经上锁的互斥上接收锁的归属权
C++ 17 还提供了更简化的写法:std::scoped_lock,表示同时锁住多个(使用模板可变参数)互斥并且在析构时全部解锁,如:
friend void swap(X& lhs, X& rhs) {
if (&lhs == &rhs) return;
std::scoped_lock guard(lhs.m, rhs.m);
swap(lhs.some_detail, rhs.some_detail);
}
即使没有锁,也可能发生死锁现象,如两个线程互相 join,会出现互相等待的情况
防范死锁的准则:
- 避免嵌套锁:假如已经拥有锁,就不要试图获取第二个锁
- 一旦持锁,就必须避免调用由用户提供的程序接口:用户提供的接口可能又上了个锁,导致嵌套锁
- 按照固定顺序加锁:如果多个锁是固定的,就必须事先规定好锁的顺序
- 使用层级锁:若已经对低层互斥加锁,那么就不准它再对高层互斥加锁。这是按照固定顺序加锁的一种特殊方式
- 将准则推广到锁之外:引起死锁的原因不一定是加锁。例如可以给线程分层级
std::unique_lock<>
std::unique_lock<> 并不一定占用与之关联的互斥
它的构造函数接受第二个参数,我们可以传入:
std::adopt_lock,表示它管理互斥上的锁,也就是直接上锁std::defer_lock,表示它在构造时不上锁,等待有需要时才会上锁(可以调用lock()方法或者交给std::lock()上锁)
std::unique_lock<> 虽然更灵活,但会占有更多空间,也比 std::lock_guard<> 略慢
它有一个 owns_lock() 方法返回是否占据互斥
它可以使用移动语义来实现互斥所有权的转移:
std::unique_lock<std::mutex> get_lock() {
extern std::mutex some_mutex;
std::unique_lock<std::mutex> lock(some_mutex);
// ...
return lock;
}
void process_data() {
std::unique_lock<std::mutex> lock(get_lock());
// do something
}
上面的这种方式可以称为通道(gate way)。如果想要访问数据,需要先取得通道类的实例(如上面的 get_lock),然后加锁,在释放时解锁
std::unique_lock 允许提前解锁
在初始化过程中保护共享数据
在单线程代码中,有时需要延迟初始化(lazy initialization),在必要时才进行初始化,如:
std::shared_ptr<some_resource> resource_ptr;
void foo() {
if (!resource_ptr) {
resource_ptr.reset(new some_resource);
}
resource_ptr->do_something();
}
假设共享数据本身就能安全地被并发访问,若将上面的代码转化成多线程形式,则仅有初始化过程需要保护
我们可以全程加锁,但是效率低,即使已经初始化了,也会加锁解锁并顺序执行
双重检验锁(double-checked locking):
std::mutex resource_mutex;
std::shared_ptr<some_resource> resource_ptr;
void foo() {
if (!resource_ptr) {
std::lock_guard lk(resource_mutex);
if (!resource_ptr) {
resource_ptr.reset(new some_resource);
}
}
resource_ptr->do_something();
}
可能会对指令重排序:分配内存、构造、赋值指针变成分配内存、赋值指针、构造。此时就会发生问题
C++ 标准库提供了 std::once_flag 类和 std::call_once() 函数,以专门处理上面的情况:
std::once_flag resource_flag;
std::shared_ptr<some_resource> resource_ptr;
void init_resource() {
resource_ptr.reset(new some_resource);
}
void foo() {
std::call_once(resource_flag, init_resource);
resource_ptr->do_something();
}
上面的代码可以保证:init_resource 函数只被一个线程执行一次
std::call_once() 的内部使用了更高效的原子操作,比 std::mutex 更轻量
与 std::mutex 类似,std::once_flag 不可移动和复制
静态变量与线程安全
静态变量初始化顺序:
- 全局变量、文件域的
static变量和类的static成员变量在main函数执行之前初始化 - 局部静态变量在第一次被使用时初始化
静态变量线程安全性:
- 非局部静态变量在
main函数前初始化,所以它们是线程安全的 - C++ 11 之前,局部静态变量不是线程安全的
- C++ 11 标准中,要求局部静态变量初始化具有线程安全性
所以,在 C++ 11 之后,线程安全的单例模式很容易实现:
my_class& my_class::get_instance() {
static my_class instance;
return instance;
}
共享互斥
C++ 中提供了两种新的互斥:
std::shared_mutex(C++ 17)std::shared_timed_mutex(C++ 14)
它们有两种加解锁方法,如 try_lock() 和 try_lock_shared(),分别表示获取独占锁和共享锁
对于这两种互斥,也可以使用 std::lock_guard<>、std::unique_lock<> 等获取独占锁
也可以通过 std::shared_lock<> 获取共享锁
共享互斥可以让多个线程都拥有锁,但是与独占锁不能共存
递归互斥
std::recursive_mutex 允许一个线程对同一实例多次加锁。我们必须先释放所有锁(加了多少次锁就得解多少次锁),才可以让另一个线程锁住该互斥
最好不要使用它
并发操作的同步
等待事件或等待其他条件
我们可以维护一个 flag 和对应的互斥,但是需要一直检查这个 flag,造成浪费。可以使用 std::this_thread::sleep_for() 来让当前线程睡几秒来缓解。这是忙等(busy-wait)
最好的方式是使用 C++ 标准库的一些工具来等待事件发生,最基本的方式是条件变量
C++ 提供了条件变量的两种实现:std::condition_variable 和 std::condition_variable_any,前者需要配合 std::mutex 使用,后者可以配合任意一种互斥使用,但是有些性能损失
std::mutex mutex;
std::queue<data_chunk> data_queue;
std::condition_variable data_cond;
void data_preparation_thread() {
while (more_data_to_prepare()) {
const data_chunk data = prepare_data();
{
std::lock_guard lock(mutex);
data_queue.push(data);
}
// 只唤醒等待队列中的一个线程
// 还有一个 notify_all,它会唤醒唤醒等待队列中所有线程
// 这里由于只添加了一个元素进去,所以唤醒一个就行了
data_cond.notify_one();
}
}
void data_processing_thread() {
while (true) {
std::unique_lock lock(mutex);
// 传入一个锁,先锁住它
// 如果后面的 lambda 表达式返回真,那么结束
// 否则,先解锁,然后阻塞线程
// 当被 notify 时,结束阻塞,重新进行上面的操作
data_cond.wait(lock, [] { return !data_queue.empty(); });
data_chunk data = data_queue.front();
data_queue.pop();
lock.unlock();
// process data
if (is_last_chunk(data)) break;
}
}
其中,如果唤醒后判断函数返回 false,称为伪唤醒(spurious wake),最好不要让判断函数带有副作用
使用 future 等待一次性任务完成
C++ 标准库有两种 future:
std::future<>:独占futurestd::shared_future<>:共享future
同一个事件只能关联唯一一个 std::future,但可以关联多个 std::shared_future
future 本身不提供同步访问,若多个线程需访问同一个 future,需要借助互斥等方式
使用 std::async() 异步执行
std::async() 可以按照异步方式启动任务,使用方式与 std::thread 相似,可以传入参数
它返回一个 std::future 对象
我们还可以给 std::async() 补充一个参数:
std::launch::deferred:在当前线程上延后调用任务函数,在wait()或get()时执行std::launch::async:启动新线程,在上面运行函数
或者两者或一下:defered | async,表示让 C++ 自行选择,这是默认参数
使用 std::packaged_tack<> 来抽象异步任务
std::packaged_tack<> 连结了 future 对象和可调用对象,它的定义大概如下:
template <typename Res, typename... ArgTypes>
class packaged_tack<Res(ArgTypes...)> {
public:
template<typename _Fn, typename = __not_same<_Fn>> // 表示 _Fn 是否是 packaged_tack 类型
explicit packaged_task(_Fn&& __fn);
future<Res> get_future();
void operator()(ArgTypes... args);
};
可以使用它来包装任务,然后传给调度器或者线程池,这就隐藏了细节,使任务抽象化
它是可调用对象,所以可以将其包装在 std::function 里面,然后传给 std::thread 对象
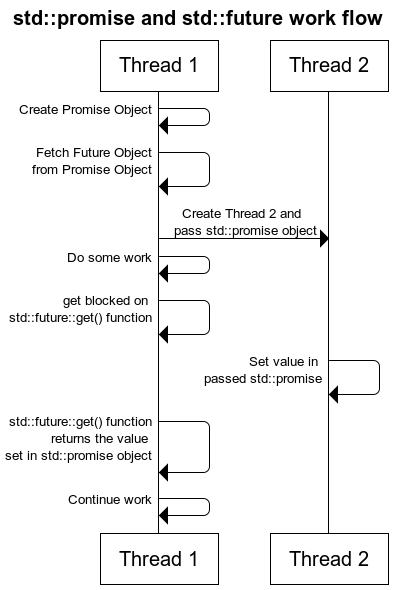
使用 std::promise
std::promise 是用来提供值的,std::future 是用来等待结果的
可以用来进行两个线程之间的通信:
将异常保存到 future 中
若经由 std::async 调用的函数抛出异常,那么这个异常会被保存到 future 中
std::packaged_task 也是这样
std::promise 也具有同样的功能,使用 set_exception() 方法:
extern std::promise<double> some_promise;
try {
some_promise.set_value(calculate_value());
} catch (...) {
some_promise.set_exception(std::current_exception());
}
如果 std::future 关联的对象(std::promise 或者 std::packaged_task)被直接销毁了,它没有返回任何值,那么 std::future 会抛出 std::future_error 异常
使用 std::shared_future 让多个线程一起等待
我们应该给每个线程都拷贝一份 std::shared_future,而不是直接使用原来的:
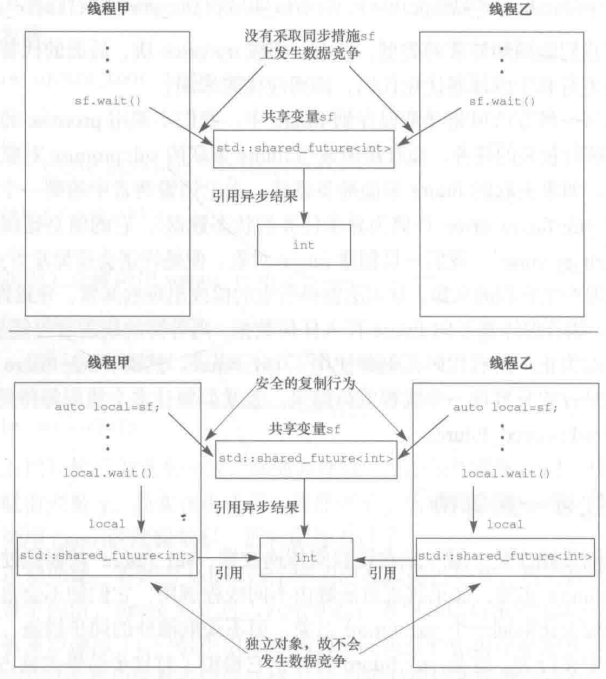
异步任务相关数据(参数、返回值等)与对应的 future、promise 等相关联,这些数据放在了某个堆数据段,用户无法访问它们。这些数据被称为共享状态(shared state)或者异步状态
future、promise 都具备 valid() 函数,用来辨别共享状态是否有效
std::shared_future 的实例根据 std::future 实例构造而得,由于 std::future 独占状态,所以需要移动语义,在移动之后,std::future 的共享状态变成了空,如:
std::promise<int> p;
std::future<int> f(p.get_future()); // 一个临时变量被移动给了 f
assert(f.valid());
std::shared_future<int> sf(std::move(f));
assert(!f.valid()); // f 被移动,不再有效
assert(sf.valid());
也可以使用 std::future 的 share() 方法得到 td::shared_future
等待多个 future
在 C++ 17 之前,使用 std::experimental::when_all() 来等待多个 future,从而避免多余的上下文切换。然而,<experimental/future> 这个头文件在 C++ 20 被干掉了
除此之外,还有 std::experimental::when_any()
限时等待
有两种超时(timeout)机制可供选择:
- 迟延超时(duration-based timeout):线程等待指定时长
- 绝对超时(absolute timeout):在某个特定时间点来临之前一直等待
一般来说 _for 结尾的是迟延超时,_until 结尾的是绝对超时
接受超时时限的函数:
std::this_thread::sleep_{for/until}()std::condition_variable下的wait_{for/until}(),还有std::cv_status::{timeout/no_timeout}std::timed_mutex、std::recursive_mutex和std::shared_timed_mutex中,加锁可以等待std::unique_lock、std::shared_lock中加锁可以等待std::future
时钟类
C++ 中,每种时钟都是一个类,包括下面的信息:
- 当前时刻:
now()静态成员函数 - 时间值的类型:
time_point成员类型 - 该时钟的计时单元长度(tick period):
period成员类型,表示为秒的分数形式,使用std::ratio<a, b>表示每 a/b 秒计数一次。并不保证与运行期实际观测的值一致 - 计时速率是否恒定,是否能够将其视为恒稳时钟(steady clock):
is_steady静态成员。std::chrono::system_lock不是恒稳的,std::chrono::steady_lock是
时钟类举例:
std::chrono::system_lock:表示系统的“真实时间”std::chrono::high_resolution_clock:高精度时钟类,最短计时单元
时长类
std::chrono::duration<> 的模板参数是:
- 第一个表示采用何种类型表示计时单元数量(如
int、double等) - 第二个表示每一个计时单元代表多少秒
例如 double 毫秒计时器:std::chrono::duration<double, std::ratio<1, 1000>>
有一些预设的时长类,如:std::chrono::nanoseconds
头文件 <ratio> 也有一些预设的分数
C++ 14 引入了 std::chrono_literals 预定义了后缀运算符,如:
using namespace std::chrono_literals;
auto one_day = 24h;
auto half_an_hour = 30min;
auto max_time_between_messages = 30ms;
使用 std::chrono::duration_cast<> 实现对时长值的显式转换,隐式转换只能从大到小(不能截断)
时长类支持算术运算
迟延超时举例:
std::future<int> f = std::async(some_task);
if (f.wait_for(std::chrono::milliseconds(35)) == std::future_status::ready) {
do_something(f.get());
}
超时时返回 std::future_status::timeout,准备就绪返回 ready,任务被延后返回 deferred
时间点类
std::chrono::time_point<> 的模板参数是:
- 第一个表示参考的时钟
- 第二个表示计时单元,默认直接用第一个参数下的:
_Clock::duration
时钟纪元:time_since_epoch() 成员函数
可以加减时长来计算新时间点,也可以两个时间点相减得到时长
线程闩和线程卡
线程闩(latch)是一个同步对象,内含一个计数器,当计数器减到 0 时,进入就绪状态。它用于等待一系列目标事件发生
C++ 20 中是 std::latch(C++ 17 之前是 std::experimental::latch),它是是线程安全的,包含:
count_down()来减计数器wait()来等待就绪is_ready()来检查是否就绪count_down_and_wait()
线程闩只能用一次,达到就绪状态后就保持不变
它的构造函数接受一个参数,表示计数器的初始值
线程卡(barrier)是可重复使用的同步构件,针对一组给定的线程,在它们之间进行同步。它的作用是让所有线程同步到一点。
在 C++ 17 之前有两种,std::experimental::{barrier/flex_barrier},在 C++ 20 中,合成了一个,即 std::barrier
线程卡构造函数接受计数器的初始值,它在完成后会自动重置,是可重复使用的
barrier(C++ 17 中的 flex_barrier)还接受第二个可选参数,表示补全函数(completion function),在线程全部运行到线程卡处时,会在其中唯一一个线程中运行该补全函数,它还提供了修改线程数目的方法
C++ 的内存模型和原子操作
标准原子类型
原子操作是不可分割的操作,意味着我们不会观察到操作处于半完成状态
C++ 中,所有的原子类型都有 is_lock_free() 成员函数,返回是否是由原子指令(atomic instruction)直接实现,还是要借助编译器和程序库的内部锁来实现
还有 is_always_lock_free 静态常量表达式成员变量,表示在编译期是否能确定是完全无锁结构(可能原子操作需要某些特定 CPU 指令,而某些设备支持另一些不支持,只有在运行期才能真正确定是否无锁)
std::atomic_flag 不提供 is_lock_free(),因为它肯定是无锁的。只有两个方法:
- 使用
test_and_set()查值并设置为真 - 使用
clear()清除
除了这个成员函数,一般还会提供:
load()、store()exchange()、compare_exchange_weak()、compare_exchange_strong()
这些成员函数可以传入内存次序语义(memory-ordering semantics),即枚举类 std::memory_order,它有 6 个取值,分别是:relaxed、acquire、consume、acq_rel、release、seq_cst
对于每个成员函数,可以选用的内存次序不同:
store():relaxed、seq_cstload():relaxed、acquire、consume、seq_cst- “读、改、写”操作:六个都可以
所有的原子操作都禁止被拷贝和移动
自 C++ 20 起,新增了 wait()、notify_one()、notify_all() 几个成员函数,与条件变量相似
std::atomic_flag
它可以用来实现自旋锁互斥(spin-lock mutex):
std::atomic_flag flag;
void lock() {
while (flag.test_and_set(std::memory_order_acquire));
}
void unlock() {
flag.clear(std::memory_order_release);
}
但是这是忙等,远非最佳选择
它不支持单纯的无修改查值操作
std::atomic<bool>
与正常不同的一点是赋值操作符,它按值返回,如:
std::atomic_bool b;
decltype(b = false) c; // bool 类型
bool b2;
decltype(b2 = false) c2; // 错误,因为引用必须赋初值
std::atomic<> 一般还有 exchange() 成员函数,与 test_and_set() 相似,它会获取原有的值,然后让我们选择新的值作为替换
还有比较交换(Compare And Swap,CAS)的操作,原子变量将传入的期望值与自身的值进行比较,如果相等就存入另一个值,否则使用原子变量自身的值更新期望值所属变量,该操作返回 bool 类型,表示是否完成了保存动作(前提是两个值相等)
有些 CPU 不支持单条指令执行该操作,此时负责的线程使用连续的指令来实现该操作,如果此线程被调度走了,那么操作就失败了,这被称为“佯败”,即尽管返回了 true 但仍然失败
C++ 中有两个成员函数:
compare_exchange_weak():有可能发生佯败,需要借助循环:bool expected = false; extern std::atomic<bool> b; while (!b.compare_exchange_weak(expected, true) && !expected);compare_exchange_strong():内部有一个循环,不会发生佯败,它确保在与期望值相等时一定能够成功更新
比较交换操作可以接受两个内存次序语义,分别对应成功和失败两种情况
std::atomic<T*>、整数原子类型与浮点原子类型
std::atomic<T*> 是指向类型 T 的指针的原子化形式
它提供了对地址的算术运算,如 +=、-=、++ 等
它还有交换相加(exchange and add)和交换相减操作:fetch_add()、fetch_sub(),和交换操作相似,它返回原来的指针而不是更新后的指针
整数原子类型除了不支持乘除外,基本与普通的整数类型相同
浮点原子类型并不支持算术原子运算
泛化的 std::atomic<> 类模板
如果要使用自定义原子类型的话,它必须具备平实拷贝赋值运算符(trivial copy-assignment operator),它的意思是支持简单的原始内存复制及其等效操作,这要求:
- 使用编译器默认提供的拷贝赋值运算符
- 不能含有任何虚函数,也不能从虚基类派生得出
- 非静态数据成员都必须具备平实拷贝赋值运算符
由于以上的限制,编译器可以使用 mempcy() 等行为来完成拷贝(如果是虚函数,那么就不能使用这个函数,会破坏虚表指针)
此外,比较交换操作采用逐位比较运算,所以并不能使用自定义的比较运算符
上述限制可以追溯到前面章节的内容,由于编译器没有能力为自定义原子类型实现无锁操作,所以它必须在内部使用锁,如果调用用户自定义的拷贝赋值、比较等函数,那么可能导致死锁
于是,编译器通过种种限制,能将自定义的类型视为原始字节,从而使得某些特定的原子类型按无锁方式具现化,增加为自定义类型直接执行原子指令的机会
在一般的平台上,如果自定义类型的大小不超过 int 或者 void*,那么基本上都支持原子指令。在某些平台上,不超过两倍也支持(被称为双字比较交换,Double Word Compare And Swap,DWCAS)。对于更大的结构,还是推荐使用互斥
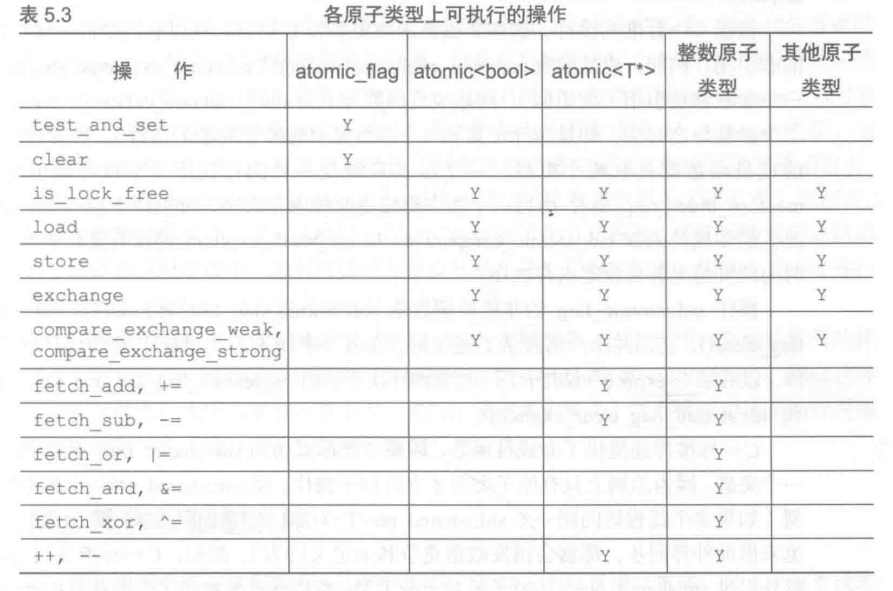
总结一下各个原子类型上可执行的操作:
智能指针原子类型
std::shared_ptr<> 的引用计数是线程安全的,但是这个变量并不是线程安全的
C++ 提供了对 std::shared_ptr<> 的特化:std::atomic<std::shared_ptr<>>
在 C++ 17 中有 std::atomic_shared_ptr<> 别名,但是 C++ 20 被干掉了
它满足上面的限制,所以有机会无锁实现
在多线程情景下,最好不要使用普通的 std::shared_ptr,使用原子化的版本可以让代码更清晰,避免数据竞争
原子操作的非成员函数
大部分非成员函数命名为 std::atomic_* 和 std::atomic_*_explicit,后者可以传入指定的内存次序
与成员函数不同的是,为了与 C 兼容,它们传入的是指针而不是引用
C++ 标准库提供了按原子化形式访问 std::shared_ptr<> 的实例,不需要使用原子化的版本,例如:
std::shared_ptr<my_data> p;
void process_global_data() {
std::shared_ptr<my_data> local = std::atomic_load(&p);
process_data(local);
}
void update_global_data() {
std::shared_ptr<my_data> local(new my_data);
std::atomic_store(&p, local);
}
注意,这里使用局部变量接收 atomic_load 的返回值是没有问题的,因为局部变量(以及返回值)只在当前线程可见,不需要跨线程,我们只需要保证跨线程的变量读取是原子操作即可
同步操作和强制次序
同步关系和先行关系
同步关系只存在于原子类型的操作之间,它的基本思想是:
对变量 x 执行原子写操作 W 和原子读操作 R,且两者都有适当的标记。如果 R 读取的值是 W 或者 W 所属线程之后的某个原子写操作写入的值,就认为它们彼此同步
实际上就是:如果一个线程需要原子读操作,那么前面必须要有一个原子写操作
先行关系是程序中确立操作次序的基本要素
在单一线程中,这个关系非常直观,就是排在前面的语句先于后面的语句执行,这是控制流程的先后关系。但是用逗号分开的单个语句没有先行关系
在多线程中,分为两部分:
- 线程间先行关系:相对简单,它依赖于同步关系。如果甲操作和乙操作分别由不同线程执行,且它们同步,则甲操作跨线程地先于乙操作发生,而且这是可传递的依赖关系
- 线程内的控制流程的先后关系
两者结合起来,就是多线程的先行关系
原子操作的内存次序
内存次序共有 6 种,它们代表三种模式:
- 先后一致次序(最严格,默认):
seq_cst - 获取——释放次序:
consume、acquire、release、acq_rel - 宽松次序:
relaxed
对第一种和第二种模式,可能会插入额外的同步指令,也可能不会,如 x86 或 x86-64 架构的 CPU 不需要额外的同步指令就能实现获取——释放次序操作的原子化
先后一致次序
- 禁止 CPU 对本操作的指令重排序
- 所有线程中的所有原子操作,必须按照一个全局一致的顺序执行(注意不会影响非原子操作,因为它们不带内存标记),形成一个全局总操作序列
对于下面的代码:
#include <assert.h>
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x() {
x.store(true, std::memory_order_seq_cst);
}
void write_y() {
y.store(true, std::memory_order_seq_cst);
}
void read_x_then_y() {
while (!x.load(std::memory_order_seq_cst));
if (y.load(std::memory_order_seq_cst)) {
++z;
}
}
void read_y_then_x() {
while (!y.load(std::memory_order_seq_cst));
if (x.load(std::memory_order_seq_cst)) {
++z;
}
}
int main() {
x = false;
y = false;
z = 0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load() != 0);
}
那么执行序列应该是这样的:
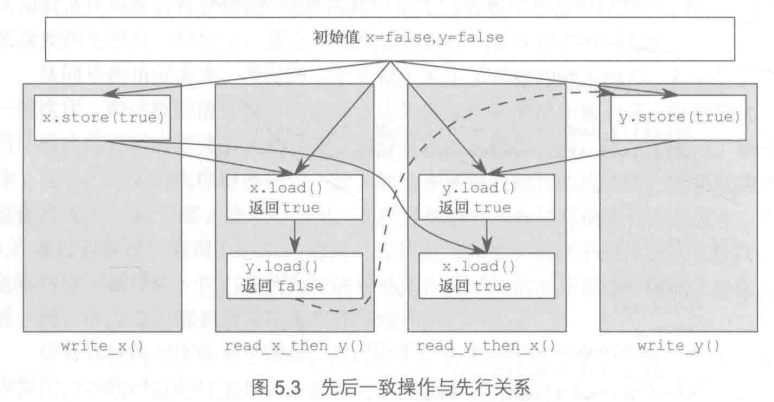
可以看成:每个线程都执行一个原子操作后,再进行下一步
在弱保序的多处理器(如 ARM)计算机上,先后一致次序会导致严重的性能损失
宽松次序
- 原子操作不存在同步关系
- 但是单一线程内同个变量上的操作仍然服从先行关系,但几乎不要求线程间存在任何次序关系
除非万不得已不要使用宽松原子操作
获取——释放次序
产生一定程度的同步效果,而不会形成全局总操作序列
acquire表示在同一个线程中,后面的任何原子操作不能重排到它前面release表示在同一个线程中,前面的任何原子操作不能重排到它后面acq_rel:上面两个都有
一些问题:
acquire不会等待release,但它保证如果release先执行,那么acquire一定能看到release之前的写入- 如果
acquire先执行,它不会阻塞,而是继续运行,可能看到旧值
不要使用 consume 次序
获取——释放次序可以限制 relaxed 次序,并且可以用来实现同步
“读——改——写”操作采用 acq_rel 次序
栅栏
栅栏(fence)用于强制施加内存次序,却无需改动任何数据
C++ 中是 std::atomic_thread_fence(),它可以传入一个内存次序语义
例如:
#include <assert.h>
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x_then_y() {
x.store(true, std::memory_order_relaxed); // 1
std::atomic_thread_fence(std::memory_order_release);
y.store(true, std::memory_order_relaxed); // 2
}
void read_y_then_x() {
while (!y.load(std::memory_order_relaxed)); // 3
std::atomic_thread_fence(std::memory_order_acquire);
if (x.load(std::memory_order_relaxed)) { // 4
++z;
}
}
int main() {
x = false;
y = false;
z = 0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load() != 0);
}
上面的代码中,两个栅栏形成了同步关系,如果不加这个栅栏,可能会出现 2 先于 1 执行或者 4 先于 3 执行的情况
它保证了 b 线程如果看到 y == true 那么一定能看到 x == true
在上面的例子中,其实可以将 x 换成非原子操作,因为两个线程不会就这个变量发生数据竞争