智能指针模板类
要创建智能指针,必须包含头文件 memory
所有智能指针都有一个 explicit 构造函数,该构造函数将指针作为参数:
shared_ptr<double> pd;
double* p_reg = new double;
pd = p_reg; // 不允许
pd = shared_ptr<double>(p_reg); // 允许
shared_ptr<double> pshared = p_reg; // 不允许
shared_ptr<double> pshared(p_reg); // 允许
智能指针不要用于非堆内存
auto_ptr 不执行深拷贝,没有所有权概念(unique_ptr),也没有引用计数(shared_ptr),因此较为简陋,容易出现问题,例如:
auto_ptr<string> ps(new string("hello"));
auto_ptr<string> vocation;
vocation = ps;
上面的代码中,两个智能指针指向同一个 string 对象,会被析构两次
可以改成 shared_ptr 使用引用计数来保证只被析构一次:
shared_ptr<string> ps(new string("hello"));
shared_ptr<string> vocation;
vocation = ps;
如果改成 unique_ptr,则第三行赋值语句直接编译报错
如果试图将一个 unique_ptr 赋值给另一个时,如果源 unique_ptr 是个临时右值,编译器允许这样做,如果源 unique_ptr 将存在一段时间,编译器将禁止这么做:
unique_ptr<string> pu1(new string("hello"));
unique_ptr<string> pu2;
pu2 = pu1; // (1) 不允许
unique_ptr<string> pu3;
pu3 = unique_ptr<string>(new string("hello")); // (2) 允许
如果想要使用 (1) 这样的代码的话可以使用 std::move(),改成:
pu2 = std::move(pu1);
这样,pu1 将不能继续使用,它被移给了 pu2
编译器如何区分区分安全与不安全呢?移动构造函数和右值引用
unique_ptr 还有 new [] 和 delete [] 的版本:
unique_ptr<double []> pda(new double(5));
标准模板库
各种 STL 容器模板都接受一个可选的模板参数,该参数指定使用哪个分配器对象来管理内存
例如 vector 模板的开头与下面类似:
template <typename T, typename Allocator = allocator<T>>
class vector { ...
如果忽略该模板参数的值,将默认使用 allocator<T>,它将使用 new 和 delete
所有的 STL 容器都提供了一些基本方法,如 size()、swap()、begin()、end()
迭代器是一种广义指针
STL 定义了一些非成员函数来执行一些操作,如:find()、swap()(通常不如成员函数效率高)、for_each()、random_shuffle()、sort()
for_each() 可以用来替换对迭代器的 for 循环,避免显式地使用迭代器变量,如:
for (vector<Review>::iterator pr = books.begin(); pr != books.end(); pr++) {
show_review(*pr);
}
for_each(books.begin(), books.end(), show_review);
上面两个等价,注意 for_each() 不能修改元素
random_shuffle() 可以随机排列区间中的元素,如:
random_shuffle(books.begin(), books.end());
注意,它要求容器支持随机访问
sort() 是排序函数,同样需要随机访问
在 C++ 11 中,还有基于范围的 for 循环:
double prices[5] = { ... };
for (double x : prices) {
...
}
for (double& x : prices) {
...
}
泛型编程
迭代器类型与层次结构
STL 定义了 5 种迭代器,并根据所需的迭代器类型对算法进行了描述,分别是:
- 输入迭代器:单通行(single-pass)的(不能对前面的迭代器值解引用),可以递增,但不能倒退。不能修改容器中的值
- 输出迭代器:不能读取值,但可以修改,也是单通行的
- 正向迭代器:只使用
++来遍历容器,是多次通行的(仍然可以对前面的迭代器值解引用,并且值不变)。可以只读,也可以可读写,取决于有没有const - 反向迭代器:具有正向迭代器的所有特性,但是可以
++也可以-- - 随机访问迭代器:具有反向迭代器的所有特征,同时添加了支持随机访问的操作和用于对元素进行排序的关系运算符

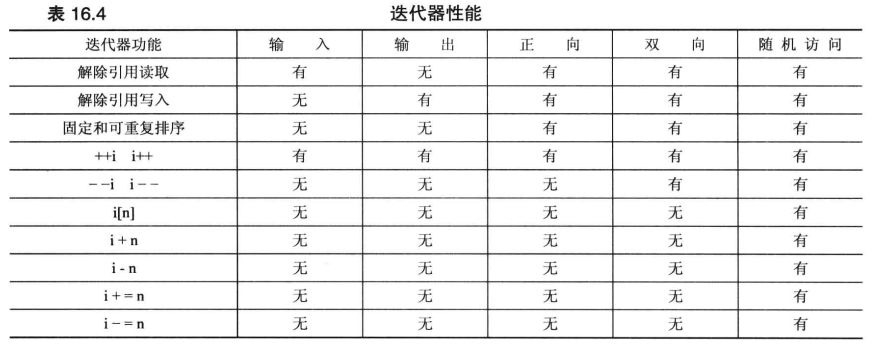
每个容器类都有一个类级 typedef 名称 iterator,如 vector<int>::iterator
概念(Concept)、改进(Refinement)和模型(Model)
STL 有若干个 C++ 无法表达的特性,如迭代器种类
虽然可以设计出具有正向迭代器特征的类,但是不能让编译器将算法限制为只使用这个类,因为常规的指针也满足这个要求
STL 文献使用术语 Concept 来描述一系列的要求
概念可以具有类似继承的关系,例如双向迭代器和正向迭代器。然而不能将 C++ 继承机制用于迭代器
有些 STL 文献使用术语 Refinement 来描述这种概念上的继承
概念的具体实现被称为 Model
ostream_iterator 和 istream_iterator:
ostream_iterator<int, char>(cout, " ");
istream_iterator<int, char>(cin);
reverse_iterator、back_insert_iterator、front_insert_iterator 和 insert_iterator
reverse_iterator 通过先递减再解引用防止在超尾处解引用
后面三个是插入相关的迭代器,将复制转换为插入
容器
容器概念有一些特征
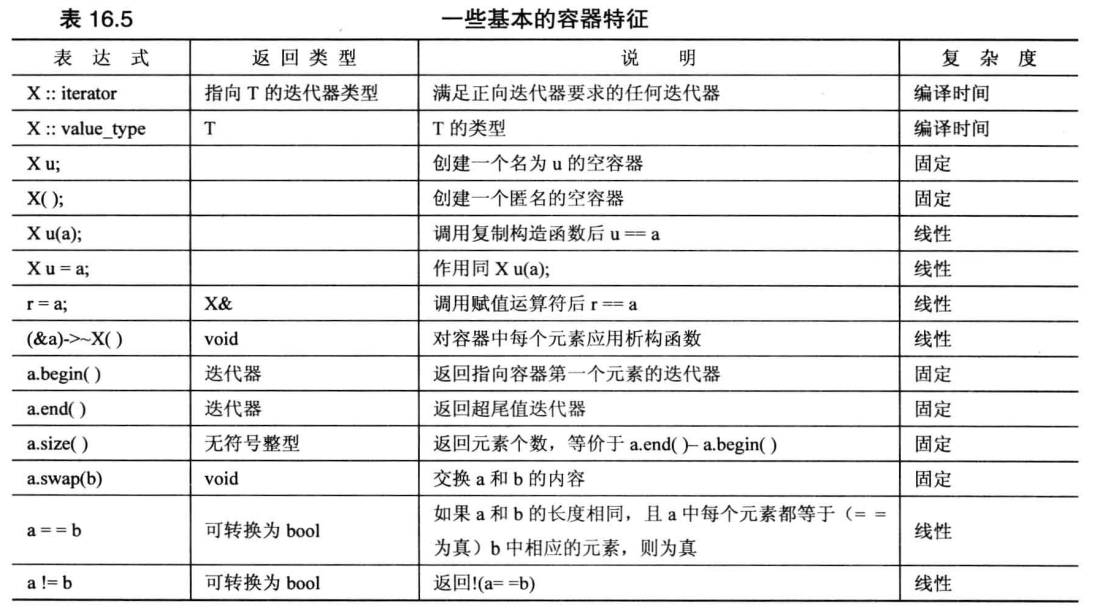

序列是容器概念的改进,它要求线性排列元素
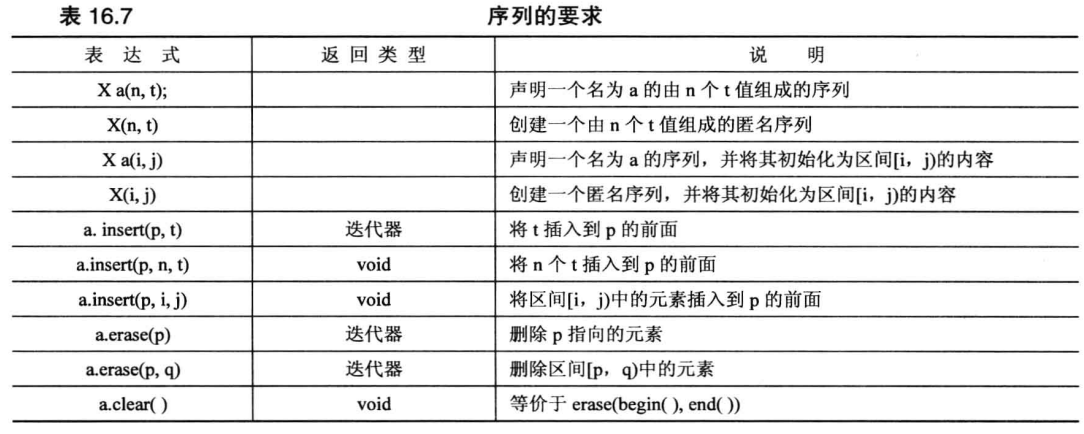
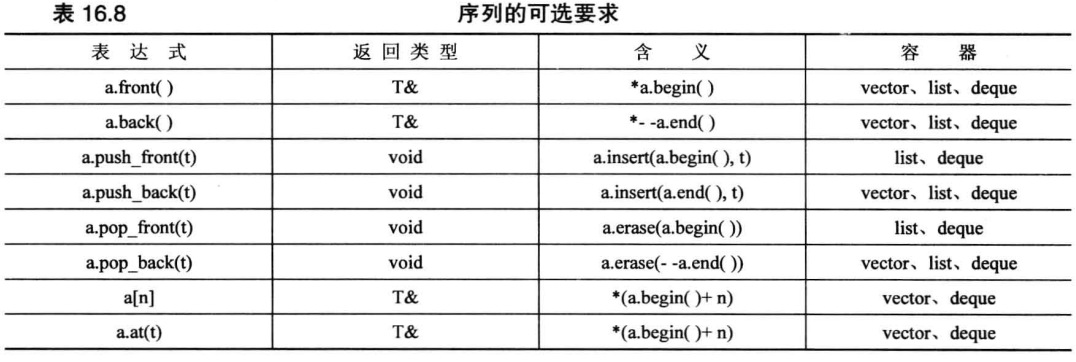
7 种序列容器:
vectordequelist:双向链表forward_list:单链表queuepriority_queue:优先队列stack
array:并非 STL 容器,因为长度固定
关联容器(associative container)是对容器概念的另一个改进,将值与键关联在一起,并使用键来查找值
4 种关联容器:
setmultiset:允许多个值的键相同的setmapmultimap:一个键可以与多个值相关联
无序关联容器(C++ 11)是对容器概念的另一个改进,基于哈希表
4 种无序关联容器:
unordered_setunordered_multisetunordered_mapunordered_multimap
函数对象
许多 STL 算法使用函数对象,也叫函数符(functor)
函数符是可以以函数方式与 () 结合使用的任意对象,包括函数名、指向函数的指针和重载了 () 运算符的类对象
例如:
template <typename InputIterator, typename Function>
Function for_each(InputIterator first, InputIterator last, Function f);
第二个模板参数可以匹配 (void*)(...) 这样的函数指针,也可以匹配函数对象
STL 定义了函数符的概念:
- 生成器(generator)是不用参数就可以调用的函数符
- 一元函数(unary function)
- 二元函数(binary function)
- 返回
bool的一元函数是谓词(predicate) - 返回
bool的二元函数是二元谓词(binary predicate)
STL 定义了多个基本的函数符(头文件 function 中),对于所有内置的算术、关系和逻辑运算符,STL 都提供了等价的函数符

STL 还有“自适应”的概念:
- 自适应生成器(adaptable generator)
- 自适应一元函数(adaptable unary function)
- 自适应二元函数(adaptable binary function)
- 自适应谓词(adaptable predicate)
- 自适应二元谓词(adaptable binary predicate)
自适应表面它携带了标识参数类型和返回类型的 typedef 成员,这些成员分别是:
result_typefirst_argument_typesecond_argument_type
好处是容易实现函数适配器,如:
binder1st(multiplies<double>(), 2.5);
上面这句话将一个二元函数变成了一元函数,将参数赋值给第一个参数,当然还有 binder2nd
算法
STL 将算法库分成 4 组:
- 非修改式序列操作:对区间中的每个元素进行操作,但是不修改容器内容
- 修改式序列操作:对区间中的每个元素进行操作,可以修改容器内容
- 排序和相关操作:包含排序函数和其他各种函数,包括集合操作
- 通用数字运算:
sum等函数
按照结果放置的位置可以对算法进行分类:
- 就地算法(in-place algorithm):结果存放到原始数据的位置
- 复制算法(copying algorithm):结果发送到另一个位置
这两种算法对迭代器的要求不同。有些算法提供两种版本,复制版本一般以 _copy 结尾
string 虽然不是 STL 的一部分,但是它考虑了 STL,因此可以使用 STL 函数
其他库
C++ 还提供了其他一些类库,例如,complex 头文件为复数提供类模板 complex,random 头文件提供了更多随机数功能
valarray 和 array
array 是为替代内置数组而设计的,提供更安全的接口,让数组更紧凑,效率更高,它提供了多个 STL 方法,如 begin()、end()
valarray 提供数值运算,没有 STL 方法,但是可以使用 begin(valarray)、end(valarray) 来获取迭代器。
可以使用下面的有趣的构造:
valarray<bool> vbool = numbers > 9; // int 数组转化为 valarray<bool>
slice 类是拓展的下标,它有三个参数:起始索引、索引数和跨距,可以这么使用:
varint[slice(1, 4, 3)] = 10;
valint[slice(0, 4, 3)] = valarray<int>(valint[slice(1, 4, 3)]) + valarray<int>(valint[slice(2, 4, 3)]);
gslice 类可以表示多维下标
模板 initializer_list(C++ 11)
如果类要用于处理长度不同的列表,那么可以创建一个接受 initializer_list 作为参数的构造函数
如果类有接受 initializer_list 作为参数的构造函数,那么 {} 语法将调用该构造函数,() 语法将使用其他构造函数,如:
std::vector<int> vi(10); // 表示 10 个元素
std::vector<int> vi{10}; // 表示一个元素 10
所有 initializer_list 元素的类型都必须相同,编译器也会进行必要的转换(int 转换为 double 之类的)