- 三角形网格(Triangle Meshes)
- 网格拓扑(Mesh Topology)
- 索引网格存储(Indexed Mesh Storage)
- 三角条带和三角扇叶(Triangle Strips and Fans)
- 网格连接性(Connectivity)的数据结构
- 场景图(Scene Graphs)
- 空间数据结构(Spatial Data Structures)
- 边界盒(Bounding Boxes)
- 层次(Hierarchical)边界盒
- 均匀空间细分(Uniform Spatial Subdivision)
- 轴对齐的二元空间划分(Binary Space Partitioning)
- BSP 树用于可见性排序
- 平铺多维数组(Tiling Multidimensional Arrays)
本章讨论一些基本的通用的数据结构,如网格结构(mesh structures)、空间数据结构(spatial data structures)、场景图(scene graphs)和平铺多维数组(tiled multidimensional arrays)
在网格方面,讨论了:
- 静态网格的存储方式
- 如何将网格传给图形 API
- 翼边数据结构( winged-edge data structure)和半边结构(half-edge structure):对管理模型的镶嵌变化很有用,例如细分和模型简化
给出了场景图的基本数据结构
对于空间数据结构,讨论了在三维空间中组织模型的三种方法:
- 边界体积层级(bounding volume hierarchies,简称 BVH)
- 层次空间细分(hierarchical space subdivision),使用层次空间细分(BSP 树)去除隐藏表面
- 均匀空间细分(uniform space subdivision)
提出了平铺多维数组,这种结构最初是为了帮助需要从磁盘交换图形数据的应用程序中的分页性能而开发的。这种结构现在对机器上内存的局部性至关重要,不管数组是否适合主存。
三角形网格(Triangle Meshes)
三角网格格(triangular meshes)、三角形网格(triangle meshes)、三角形不规则网络(triangular irregular networks,TINs)这几个指的是同一个东西
处理这些东西对于图形系统的性能至关重要
最小化消耗的存储量,可以减小将它们传递给图形系统的带宽,带宽比存储更加宝贵
除了存储和简单绘制(如细分、网格编辑、网格压缩等)之外,对邻接信息的高效访问至关重要
三角形网格通常用于表示表面,因此三角形网格是通过公共顶点和公共边相互连接而成的连续表面,与许多零散的三角形相比,可以更有效地进行处理
顶点存各种属性然后进行插值,按面存属性也很重要
网格拓扑(Mesh Topology)
网格拓扑:三角形连接在一起的方式
网格是类表面的,这可以形式化为网格拓扑的约束
很多算法只能再具有可预测连接的网格上工作,或者更加容易实现
对网格拓扑最严格的要求是表面必须是流形(manifold,表面没有缝隙,“不透水”)
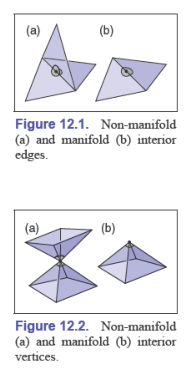
如何检查网格是否是流形的:
- 所有的边都刚好被两个三角形共享
- 所有的顶点被一圈完整的三角形共享
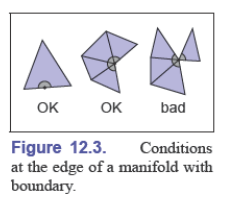
流形网格很方便,但有时必须允许网格有边界,我们可以放宽要求:
- 所有的边都被一个或者两个三角形共享
- 所有的顶点都连接到 a single edge-connected set of triangles(不知道怎么更好地翻译这句话)
如何区分表面的朝向(orientation)?根据三个顶点的排列顺序,逆时针顺序是正面(有的逆时针是正面)
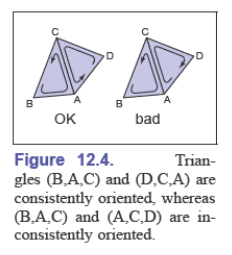
当所有三角形都遵循相同的内外朝向判断时,称三角形网格是一致定向的(consistently oriented)
在一致定向的三角形网格中,公共边的两个顶点在两个三角形中以相反的顺序出现
任何有非流形边的网格都不能一致地定向
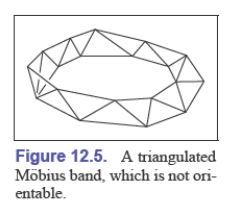
一个拥有边界的曲面也有可能是一个有效的流形,但是却没有一致的方法来确定方向,这些称为不可定向表面,如莫比乌斯带
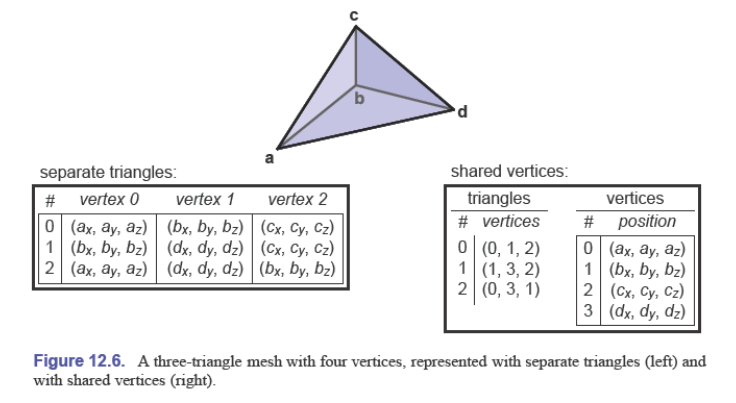
索引网格存储(Indexed Mesh Storage)
每个三角形分开存储会让 b 点存储三次
使用共享顶点的方式进行存储:三角形仅存顶点的索引,称为索引三角形网格(indexed triangle mesh)
Mesh {
int tInd[nt][3];
Vec3 verts[nv];
}
可以计算一下这两种存储方式占用的空间:
- 分开存储的三角形:$9n_t$
- 索引三角形:$3n_v+3n_t$
用哪个取决于 $n_v$ 与 $n_t$ 的比值
在大型网格中,每个顶点大约平均连接六个三角形,根据这个比值,发现索引三角形所占空间更少
三角条带和三角扇叶(Triangle Strips and Fans)
索引三角形是最常用的表示方法,因为它很好地平衡了简单性、便利性和紧凑性,这经常被用于在应用程序和图形管线之间传递网格
在应用程序中,可以使用更加紧凑的存储方式,如三角条带和三角扇叶
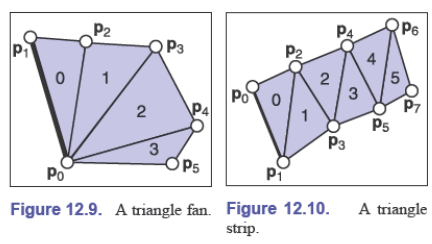
左边的三角形网格如果使用索引三角形,那么一共会存储 $12$ 个顶点索引,但是我们可以存储成 $[t_0,t_1,\dots,t_5]$ 的形式(公共点和其他顶点),这样就只需要存 $6$ 个顶点索引
同样地,右边的三角形网格也可以存储成 $[t_0,t_1,\dots,t_7]$ 的形式,每三个相邻的索引建立一个三角形,但是需要考虑一致定向,对顶点进行反转
随着条带增长,相对存储大小会迅速减小
网格连接性(Connectivity)的数据结构
索引网格、条纹三角形和扇形都是静态网格的良好的紧凑表示。然而,它们不允许修改网格。为了有效地编辑网格,需要更复杂的数据结构来回答以下问题:
- 给一个三角形,如何找到相邻的三个三角形
- 给一条边,如何找到以它为公共边的两个三角形
- 给一个顶点,如何找到以它为公共点的这些面
- 给一个顶点,如何找到以它为公共点的边
最直接的实现(尽管过于臃肿)就是直接定义三种类型:顶点、边和三角形,并直接存储所有关系
Triangle {
Vertex v[3]
Edge e[3]
}
Edge {
Vertex v[2]
Triangle t[2]
}
Vertex {
Triangle t[]
Edge e[]
}
上面只是示例,实际存储的信息会多很多
需要可变长度的数据结构,这些数据结构效率通常较低
与其显式地存储这些关系,不如定义接口,接口后面隐藏一个更加高效的数据结构
边和三角形需要的存储空间是固定的(边只需要两个顶点,三角形只需要三个顶点)。在多边形网格中,没有三角形,所以通常都是基于边的。而在三角形网格中,可以基于三角形和边
紧凑性、高效的邻接查询(时间复杂度不应该依赖于网格大小),这一节有三种网格数据结构,一种基于三角形,两种基于边
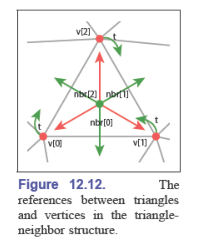
三角形——邻居(Triangle-Neighbor)结构
在每个三角形中存储三个相邻三角形的指针(需要按一定的顺序)
在每个顶点上存储任意一个相邻三角形的指针
可以表示成:
Triangle {
Triangle nbr[3];
Vertex v[3];
}
Vertex {
// 其他关于顶点的数据
Triangle t; // 任意一个相邻三角形
}
在索引网格中,可以增加两个数组来实现:
Mesh {
// 其他关于顶点的数据,包括顶点的位置等等
int tInd[nt][3]; // 三角形
int tNbr[nt][3]; // 每个三角形的三个相邻三角形的索引
int vTri[nv]; // 每个顶点的任意一个相邻三角形
}
回看之前的四个问题:
- 三角形的相邻三角形:可以直接读取
- 边的相邻的三角形:与找顶点的相邻三角形相似
- 顶点的相邻三角形:从
vTri[i]这个三角形出发,顺时针或者逆时针一直找三角形即可 - 顶点的相邻边:与找顶点的相邻三角形相似
这个结构非常紧凑
仅适用于流形三角形网格,对于有边界的,可以引入哨兵节点 $-1$,边界上顶点也不能选择任意相邻三角形,需要选择最逆时针或者最顺时针的三角形
翼边(Winged-Edge)结构
基于边的结构,并不是只有三角形网格可用
每个边存储:
- 它连接的两个顶点的索引
- 以它为公共点的两个三角形的按照逆时针遍历的下一条和前一条边
对于每个顶点和面,还存储一个指向连接到它的任意边的指针
这个图有点问题,左侧上下标反了:
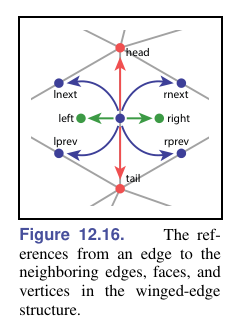
数据结构表示如下:
Edge {
Edge lprev, lnext, rprev, rnext;
Vertex head, hail;
Triangle left, right;
}
Triangle {
// 其他关于三角形的数据
Edge e; // 任意一个相邻的边
}
Vertex {
// 其他关于顶点的数据
Edge e; // 任意一个相邻的边
}
回答前面的四个问题:
- 三角形的相邻三角形:
Triangle.e先拿到任意一条边,然后一直找lnext或者rnext(根据Edge的left和right来看当前三角形是左侧还是右侧) - 边的相邻的三角形:直接读
- 顶点的相邻三角形:与顶点的相邻边相似
- 顶点的相邻边:
Vertex.e先拿到任意一条边,一直取lnext(?)
与任何数据结构一样,翼边数据结构需要进行各种时间/空间权衡。例如可以删除 lprev 和 rprev,这样会减少空间复杂度,增加时间复杂度
半边(Half-Edge)结构
翼边结构相当优雅,但是有一个缺点,就是每次拿到边的时候需要检查边的方向(就是看当前是从 head 还是从 tail 进入的),因为这会影响判断 left 和 right
解决方案就是存储半条边的数据,每条边被分成两条半边:
- 包含该半边对应的顶点
- 每个半边被分配一个三角形
- 包含一个指向被分配的三角形的下一条边的索引
- 需要知道另一个半边
每个三角形和顶点也都包含任意一个相邻的半边
表示成这样:
HEdge {
HEdge pair, next;
Vertex v;
Triangle t;
}
Triangle {
// 其他关于三角形的数据
HEdge h; // 任意一个相邻的半边
}
Vertex {
// 其他关于顶点的数据
HEdge h; // 任意一个相邻的半边
}
遍历半边结构就和翼边相似
如果基于数组的实现,那可以省略 pair
除了本章中介绍的简单遍历算法外,所有这三种网格拓扑结构都可以支持各种网格操作,如分割或折叠顶点、交换边、添加或删除三角形。
场景图(Scene Graphs)
三角形网格管理管理一组三角形,这些三角形构成场景中的一个对象
在这之上还要进行场景的管理,对象需要通过一系列的转换来将它放在正确的位置上,复杂的场景会包含大量的转换,需要良好的组织它们
大多数场景有一个层次组织,这些变换可以根据层次结构,使用场景图来管理
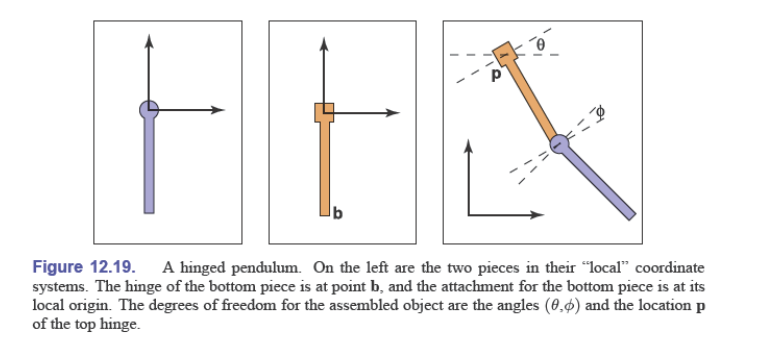
对于这个铰接摆,我们令:
$$ \begin{aligned} \mathbf M_\theta&=\mathrm{rotate}(\theta)\\ \mathbf M_\phi&=\mathrm{rotate}(\phi)\\ \mathbf M_p&=\mathrm{translate}(\vec {p})\\ \mathbf M_b&=\mathrm{translate}(\vec {b}) \end{aligned} $$那么对于上面的部分,使用矩阵:
$$ \mathbf M_1=\mathbf M_p\mathbf M_\theta $$对于下面的部分:
$$ \mathbf M_2=(\mathbf M_p\mathbf M_\theta)\mathbf M_b\mathbf M_\phi $$我们发现这样是一个层次结构
在光栅化中
使用栈的思想,利用 push 和 pop 操作实现
function traverse(node)
push(M_local)
使用栈中矩阵的组合绘制对象
traverse(left child)
traverse(right child)
pop()
在光线追踪中
在光线追踪中,可以选择求交的空间:如果变换矩阵是 $\mathbf M$,那么对于一条射线 $\vec a+t\vec b$,我们可以直接对射线进行变换:
$$ \mathbf M^{-1}\vec a+t\mathbf M\vec b $$这样的射线与未进行变换的几何体相交,可能会更简单(例如圆,圆变换后可能变为椭圆)
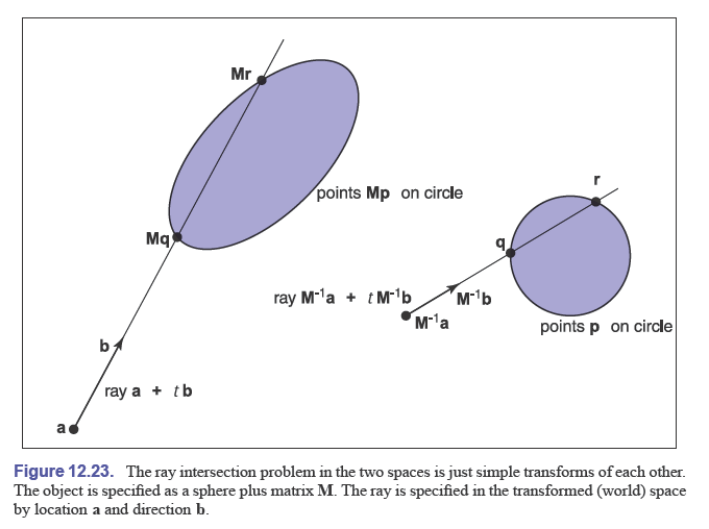
基于这个想法,我们可以改进光线追踪得求交程序:
instance::hit(ray a + t * b, real t0, real t1, hit-record rec)
ray rt = M ^ (-1) * a + t * M ^ (-1) * b
if (base-object->hit(rt, t0, t1, rec)) then
rec.n = (M ^ (-1)) ^ T * rec.n
return true
else
return false
空间数据结构(Spatial Data Structures)
在许多图形程序中,快速定位特定空间中的集合对象的能力很重要。摄像机需要知道可见的几何体,物理引擎需要进行碰撞检测。这些都可以由各种空间数据结构来支持。
空间数据结构组织空间中的对象,以便进行高效的查找
这一节会讨论三种一般类型的空间数据结构的例子。
划分方案整体上有两种:
- 物体划分方案(object partitioning schemes):对象被分成组,但是组在空间中可能有重叠
- 空间划分方案(space partitioning schemes):空间被分成多个部分,但是一个对象可能与多个部分有交。划分可以规则也可以不规则
这一节会以光线追踪为主要背景:光线追踪在求交点时需要 O(N) 遍历,如果使用适当的数据结构,可以使用分治来提高效率
这一节主要讨论三种:
- 边界体积层级(bounding volume hierarchies)
- 均匀空间细分(uniform space subdivision)
- 二元空间划分(binary space partitioning)
边界盒(Bounding Boxes)
关键操作是计算射线与边界框的相交,这与传统的相交测试不同,我们不需要知道交点的位置,我们只需要知道它是否命中盒子
先考虑二维,二维的边界盒可以表示成:
$$ (x,y)\in[x_\text{min},x_\text{max}]\times[y_\text{min},y_\text{max}] $$在 $x$ 与 $y$ 两个维度上分别计算 $t$ 的范围,例如:
$$ \begin{aligned} t_\text{xmin}&=\frac{x_\text{min}-x_e}{x_d}\\ t_\text{xmax}&=\frac{x_\text{max}-x_e}{x_d} \end{aligned} $$然后我们看两个范围有没有交集,如果有交集说明有交点
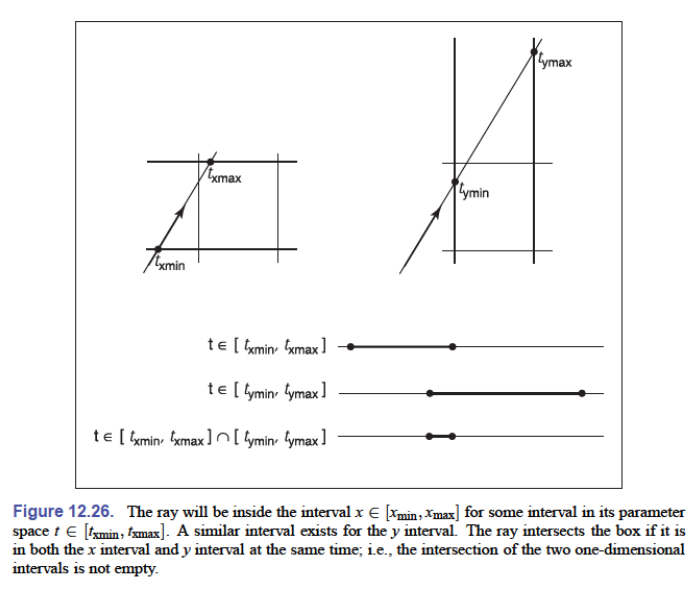
上面讨论的是 $x_d,y_d>0$ 的情况,如果 $x_d\lt 0$,那么需要交换 $t_\text{xmin}$ 与 $t_\text{xmax}$
所以代码可以写成:
if (x_d >= 0) then
t_xmin = (x_min - x_e) / x_d, t_xmax = (x_max - x_e) / x_d
else
t_xmin = (x_max - x_e) / x_d, t_xmax = (x_min - x_e) / x_d
if (y_d >= 0) then
t_ymin = (y_min - y_e) / y_d, t_ymax = (y_max - y_e) / y_d
else
t_ymin = (y_max - y_e) / y_d, t_ymax = (y_min - y_e) / y_d
if (t_xmin > t_ymax) or (t_ymin > t_xmax) then
return true
else
return false
另外,如果 $x_d=0$,会出现除以 $0$ 的情况,用 IEEE 浮点数的约定可以正确地、优雅地处理:
- 如果 $x_e\le x_\text{min}\le x_\text{max}$,$t_\text{xmin}$ 与 $t_\text{xmax}$ 都是 $+\infty$,不可能有交集
- 如果 $x_\text{min}\le x_e\le x_\text{max}$,$t_\text{xmin}$ 是 $-\infty$,$t_\text{xmax}$ 是 $+\infty$,是否有交点取决于 $y$
- 第三种情况同理
不过,当 $x_d=-0$ 时上面的代码会出错,需要预先取个倒数,令 $a=1/x_d$:
a = 1 / x_d
if (a >= 0) then
t_xmin = a * (x_min - x_e), t_xmax = a * (x_max - x_e)
else
t_xmin = a * (x_max - x_e), t_xmax = a * (x_min - x_e)
不懂,在这一篇翻译中给出解释如下:
$-0$ 在 IEEE 标准中视为负的无穷小 在判断(x_d >= 0)时为 true,然后走上分支,实际上应该走下分支。通过 1 / x_d,变成负的无穷大,则可以正常地在走下分支。
层次(Hierarchical)边界盒
为了减少计算次数,使用树形结构实现层次边界盒:
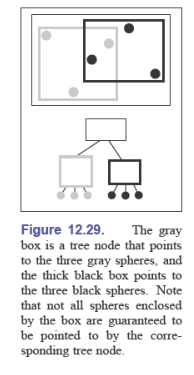
这样可以保证:当射线未击中大框时,也不可能击中其中的小框
大概的伪代码如下:
class bvh-node : surface
virtual bool hit(ray e + t * d, real t0, real t1, hit-record rec)
virtual box bouding-box()
surface-pointer left
surface-pointer right
box bbox
function bool bvh-node::hit(ray e + t * d, real t0, real t1, hit-record rec)
if (bbox.hitbox(a + t * b, t0, t1)) then
// 如果击中了当前这个大边界框,那么尝试击中两个儿子
hit-record lrec, rrec
left-hit = (left != nullptr) and (left->hit(a + t * b, t0, t1, lrec))
right-hit = (right != nullptr) and (right->hit(a + t * b, t0, t1, rrec))
if (left-hit and right-hit) then
// 如果两个都击中了,那么返回最近的那一个
if (lrec.t < rrec.t) then
rec = lrec
else
rec = rrec
return true
else if (left-hit) then
rec = lrec
return true
else if (right-hit) then
rec = rrec
return true
else
return false
else
return false
搞完怎么使用层次边界盒后,看一下如何创建层次边界盒
创建时需要让树大致平衡,并且子树的重叠不太多,其中一种启发式方法是每次沿着特定的轴进行排序(其实就是 KDTree)
除了排序之外,还可以按照中点进行划分(比排序更快)
这个划分方法就叫做边界体积层级(bounding volume hierarchies),是一个按照对象的划分方法
均匀空间细分(Uniform Spatial Subdivision)
另一个减少相交测试的策略是按照空间进行划分
在均匀的空间细分中,场景被划分为轴线对齐的大小相同的(不一定是正方体)盒子
和前面一样,这些盒子可以是 surface 的子类
这些盒子放在一个数组中,其中没有对象的盒子在数组中是空指针,否则可以是列表啥的数据结构
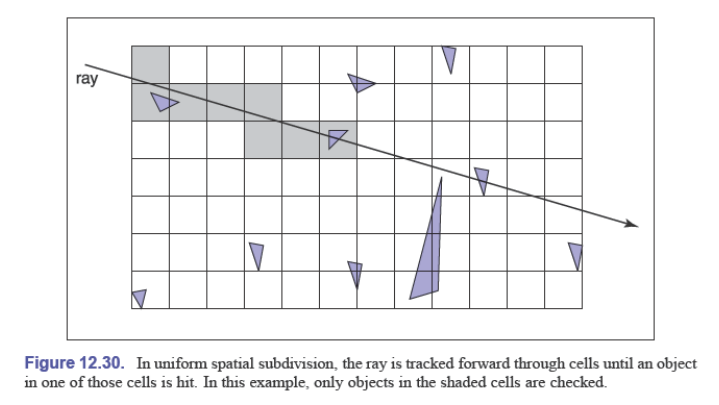
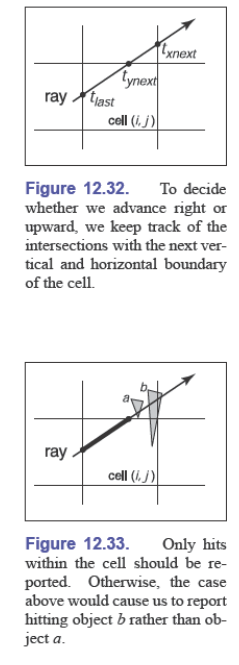
先找到第一个被击中的单元格的索引,从它开始遍历之后被击中的盒子(可以使用增量的方法),找到被击中的盒子和在这个盒子中 $t$ 的取值范围
轴对齐的二元空间划分(Binary Space Partitioning)
我们也可以在分层数据结构中划分空间,例如二元空间划分树(BSP 树),其中最常见的是轴对齐切平面(而非多边形对齐切平面)
在 BSP 中,每个节点都包含一个切平面(cutting plane)和它的两个子树
假设切平面为 $x=D$,那么对于射线 $\vec p=\vec e+t\vec d$ 来说,在 $[t_0,t_1]$ 中找交点有四种情况:
- 起始点在 $x=D$ 左侧,并且方向向左,即 $x_e+t_0x_d
- 起始点在 $x=D$ 左侧,并且方向向右,即 $x_e+t_0x_d
- (与第一种情况相似)起始点在 $x=D$ 右侧,并且方向向右,即 $x_e+t_0x_d>D$ 且 $x_d>0$。此时只需测试右子树
- (与第二种情况相似)起始点在 $x=D$ 右侧,并且方向向左,即 $x_e+t_0x_d>D$ 且 $x_d<0$。此时需先测试右子树,如果无交点则测试左子树
- 起始点在 $x=D$ 左侧,并且方向向右,即 $x_e+t_0x_d
可以令 $x_p=x_e+t_0x_d$,大概的伪代码如下:
class bsp-node : surface
virtual bool hit(ray e + t * d, real t0, real t1, hit-record rec)
virtual box bouding-box()
surface-pointer left
surface-pointer right
real D // 切平面
function bool bsp-node::hit(ray e + t * d, real t0, real t1, hit-record rec)
x_p = x_a + t0 * x_b
if (x_p < D) then
if (x_b < 0) then
// 第一种情况
return (left != nullptr) and (left->hit(a + t * b, t0, t1, rec))
else
// 第二种情况
t = (D - x_a) / x_b // 计算切平面对应的 t
if (t > t_1) then
// 射线不能到达切平面的右侧
return (left != nullptr) and (left->hit(a + t * b, t0, t1, rec))
else
// 射线可以到达切平面的右侧
if (left != nullptr) and (left->hit(a + t * b, t0, t, rec)) then
// 射线击中了左侧的对象
return true
else
// 射线没有击中左侧对象,检测右侧
return (right != nullptr) and (right->hit(a + t * b, t, t1, rec))
else
// 第三、四种情况类似
上面的代码只考虑了 $x$ 轴,可以将 x_p = x_a + t0 * x_b 变成 u_p = u_a[axis] + t0 * u_b[axis] 来实现更换其他轴
BSP 树用于可见性排序
前面的 BSP 树是以对象为单位的,而在这一节,使用 BSP 树来进行面元的可见性排序,而且当视点变化时 BSP 树的结构不变
与前面不同,这里的 BSP 树使用非轴向对齐的切平面(cutting plane),这样可以使切平面与多边形面元的方向一致
BSP 算法概述
BSP 树算法适用于任何由多边形组成的场景,在这个场景中不能有多边形穿过任意由其他多边形定义的平面
下面讨论三角形面元的情况,可以推广到多边形
假设视点为 $\vec e$,有两个三角形 $T_1$、$T_2$,我们假设 $T_2$ 在 $T_1$ 的左侧:
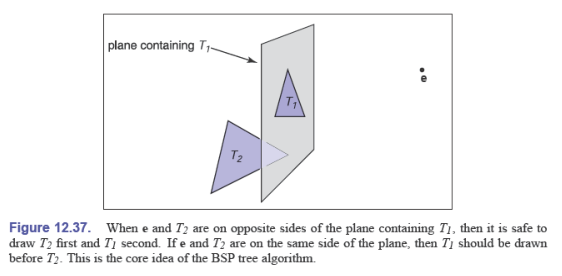
设 $T_1$ 的所在平面的隐式方程为 $f_1(\vec p)=0$,以它当做切平面,有:
- 若 $f_1(\vec e)\lt 0$,说明视点在 $T_1$ 的右侧,那么先绘制 $T_2$ 再绘制 $T_1$
- 若 $f_1(\vec e)> 0$,说明视点在 $T_1$ 的左侧,那么先绘制 $T_1$ 再绘制 $T_2$ 是没有问题的
- 等于 $0$ 的话其实无所谓
我们按照上面的规则建一棵树,以根节点对应的三角形为切平面,推广到多个三角形
function draw(bsptree tree, point e)
if (tree.empty) then
return
if (f_root(e) < 0) then
// 如果视点在左侧,依次绘制右子树、root 对应的三角形、左子树
draw(tree.plus, e)
rasterize tree.triangle
draw(tree.minus, e)
else
// 如果视点在右侧,依次绘制左子树、root 对应的三角形、右子树
draw(tree.minus, e)
rasterize tree.triangle
draw(tree.plus, e)
但是,在实际中,三角形不可能可以这么简单地分成两部分,总有三角形可以穿过切平面,这时可以将穿过切平面的三角形分成小三角形
构建 BSP 树
由于共享顶点很常见,需要很小心地考虑精度的问题
tree-root = node(T1)
for i in range(2, N) do
tree-root.add(Ti)
function add(Triangle T)
fa = f(a)
fb = f(b)
fc = f(c)
if (abs(fa) < epsilon) then
fa = 0
if (abs(fb) < epsilon) then
fb = 0
if (abs(fc) < epsilon) then
fc = 0
if (fa <= 0 and fb <= 0 and fc <= 0) then
// 在左侧
if (左子树为空) then
negative-subtree = node(T)
else
negative-subtree.add(T)
else if (fa >= 0 and fb >= 0 and fc >= 0) then
// 在右侧
if (右子树为空) then
positive-subtree = node(T)
else
positive-subtree.add(T)
else
切割三角形并且放到对应的那一边
切割三角形
为了写出更加简洁的代码,让顶点 $\vec c$ 在一边,另外两个顶点在另一边,这样将多种情况合并成一种
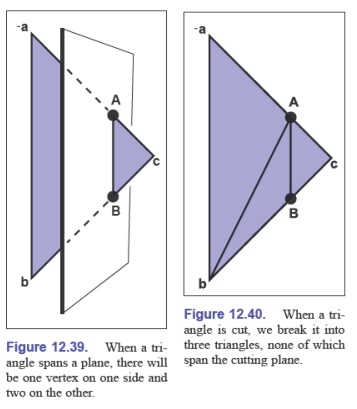
if (fa * fc >= 0) then
// 如果 a 和 c 在同一边或者都在切平面上,三个顶点应该从 a,b,c 变成 c,a,b
swap(fb, fc), swap(b, c)
swap(fa, fb), swap(a, b)
else if (fb * fc >= 0) then
// 如果 b 和 c 在同一边或者都在切平面上,三个顶点应该从 a,b,c 变成 b,c,a
swap(fa, fc), swap(a, c)
swap(fa, fb), swap(a, b)
// 计算切出来的两个顶点
compute A, B
// 得到三个小三角形,需要保证顶点顺序
T1 = (a, b, A), T2 = (b, B, A), T3 = (A, B, c)
// 将三个小三角形放到对应的子树中
if (fc >= 0) then
negative-subtree.add(T1)
negative-subtree.add(T2)
positive-subtree.add(T3)
else
negative-subtree.add(T1)
positive-subtree.add(T2)
negative-subtree.add(T3)
如果某个顶点位于切平面上,其中一个小三角形的面积就是零,这样光栅器是可以处理的,或者可以添加一个零面积三角形检测
现在来看如何计算出两个交点,使用平面的隐式方程:
$$ \vec n\cdot(\vec a + t(\vec c-\vec a))+D=0 $$一条边的函数为:
$$ \vec p(t)=\vec a+t(\vec c-\vec a) $$联立可以计算出 $t$:
$$ t_A=-\frac{\vec n\cdot\vec a + D}{\vec n \cdot(\vec c-\vec a)} $$那么:
$$ \vec A=\vec a+t_A(\vec c-\vec a) $$优化 BSP 树
树的创建效率不太会关心,因为这只是个预处理
运行的效率取决于三角形的个数,由于会切割成小三角形,所以运行效率与将三角形添加到树中的顺序有关
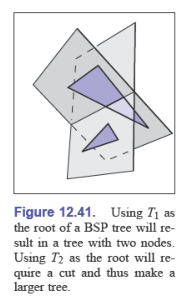
很难找到添加到树中的三角形的最佳顺序,全排列需要阶乘级别的复杂度
可以随机找几个排列,然后从中找到最好的
将三角形分割成三角形和凸四边形可能会更有效
平铺多维数组(Tiling Multidimensional Arrays)
有效利用内存层次结构是设计现代体系结构算法的一项关键任务
平铺(tiling)也可以叫做砖块化(bricking)
传统的二维数组以一维数组的形式存储,依靠索引来读取,但是这样虽然同一行是连续的,但是同一列的相邻元素却有间隔,这会导致内存局部性不平等的问题(与缓存机制有关)
对此的解决方案是使用平铺使行和列的内存局部性更加平等
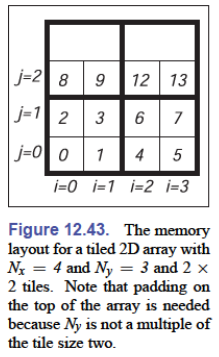
块的大小应该与机器上的内存单元大小相似
二维数组的一级平铺(One-Level Tiling for 2D Arrays)
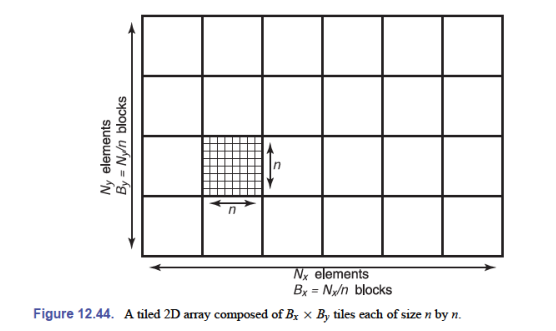
假设有 $N_x\times N_y$ 大小的数组,每一块的大小为 $n\times n$,那么对于块来说,数组大小为(假设可以整除,如果不能整除需要进行填充):
$$ \begin{aligned} B_x=N_x/n\\ B_y=N_y/n \end{aligned} $$对于 $(x,y)$ 这个元素,所在块的索引为:
$$ \begin{aligned} b_x=x\div n\\ b_y=y\div n \end{aligned} $$其中,$\div$ 表示整数除法,丢弃小数部分
在块内,$(x,y)$ 的索引为:
$$ \begin{aligned} x'=x\bmod n\\ y'=y\bmod n \end{aligned} $$那么这样可以算出在平铺的一维数组的中索引:
$$ \begin{aligned} \text{index}&=n^2(B_xb_y+b_x)+y'n+x'\\ &=n^2((N_x\div n)(y\div n)+x\div n)+(y\bmod n)n+x\bmod n \end{aligned} $$表达式包含许多整数乘法、除法和取模操作,这些操作在某些处理器上开销很大
当 $n$ 是 $2$ 的幂时,这些运算可以转换为位移位和位逻辑运算
然而,如上所述,理想的大小并不总是 $2$ 的幂。有些乘法运算可以转换为移位/加法运算,但除法和取模运算更成问题。可以增量地计算索引,但这将需要跟踪计数器,并且需要进行大量比较和较差的分支预测性能
然而,有一个简单的方法:
$$ \text{index}=F_x(x)+F_y(y) $$其中:
$$ \begin{aligned} F_x(x)=n^2(x\div n)+(x\bmod n)\\ F_y(y)=n^2(N_x\div n)(y\div n)+(y\bmod n)n \end{aligned} $$预先计算 $F_x$ 和 $F_y$ 并将其制成表,总共需要存储 $N_x+N_y$ 个数据,所以即使数据集非常大,表的总大小也能够容纳在处理器的主数据缓存中
三维数组的二级平铺(Two-Level Tiling for 3D Arrays)
有效的 TLB(快表)利用率也正在成为算法性能的一个关键因素
通过创建 $m\times m\times m$ 个 $n \times n\times n$ 个单元的块,可以使用相同的技术来提高三维数组中的 TLB 命中率
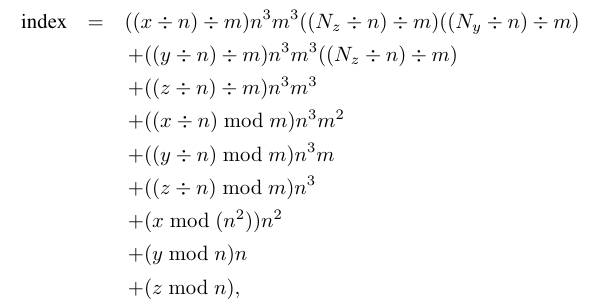
同样地,也可以预先存表:
