§ 参考资料 共 1 条
渲染管线的架构
在实时渲染领域可以找到流水线结构,一种粗略的划分方法是将渲染管线分成四个阶段:
- 应用阶段(application):是由应用程序进行驱动的,运⾏在通⽤ CPU 上,由于 CPU 通常具有多核心,可以高效地进行处理,⼀般 CPU 会负责碰撞检测、全局加速算法、动画、物理模拟等任务
- 几何处理阶段(geometry processing):负责处理变换(transform)、投影(projection)以及其他所有和几何处理相关的任务。需要计算哪些物体会被绘制、应该如何进⾏绘制、应当在哪⾥绘制等问题。通常运⾏在 GPU 上,它包含⼀系列的可编程单元和固定操作硬件
- 光栅化阶段(rasterization):以三⻆形的三个顶点作为输入,找到所有位于三⻆形内部的像素,并将其转发到下⼀个阶段中,完全运行在 GPU 上
- 像素处理阶段(pixel processing):决定像素的颜⾊、执行深度测试来判断像素的可见性、像素颜色混合等
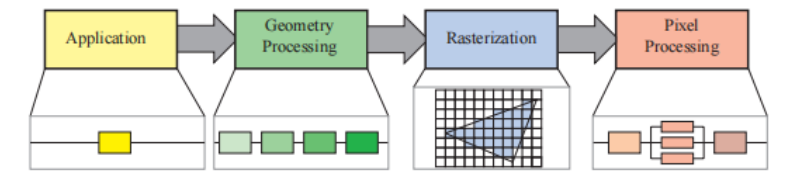
这个结构(渲染管线的引擎)是实时计算机图形程序的核⼼,也是后续章节的基础概念
每个阶段本身通常也是⼀个流⽔线,这意味着每个阶段也是由几个子阶段构成的
FPS(每秒帧数)、Hz(硬件刷新率)
应用阶段
通常运行在 CPU 上,但是某些任务也可以让 GPU 来执行,即通过一种叫做计算着色器(compute shader)的独立模式,该模式会将 GPU 视为⼀个⾼度并行的通⽤处理器,⽽忽略其专门⽤于图形渲染的特殊功能
在应用阶段的最后,需要进行渲染的几何物体会被输入到几何处理阶段,这些几何物体被称为渲染图元(rendering primitive),即点、线和三角形。这时应用阶段最重要的任务
由于这一阶段基于软件实现(software-based),它并没有像之后的阶段一样进一步划分出子阶段
多核调度
碰撞检测(collision detection)、处理输入、一些特殊的剔除算法,以及渲染管线剩余部分无法处理的⼀切问题都会在应用阶段完成
几何处理阶段
负责大部分的逐三角形(per-triangle)、逐顶点(per-vertex)操作
可以将该阶段再细分下去,可以划分为:
- 顶点着色(vertex shader)
- 投影(projection)
- 裁剪(clipping)
- 屏幕映射(screen mapping)
在顶点着色(vertex shader)处理完成后,还有几个可以在 GPU 上执行的可选操作:
- 曲面细分(tessellation)
- 几何着色(geometry shader)
- 流式输出(stream out)
顶点着色和这几个可选阶段完成后,都会输出一组齐次坐标表示的顶点,并输入到下一阶段中
顶点着色
顶点着色的任务主要有两个:计算顶点的位置、计算顶点的属性(例如法线、纹理坐标等)
之前都是逐顶点着色,随着现代 GPU 的发展,顶点着色阶段越来越通用
模型变换、观察变换、投影变换
裁剪坐标系(clip coordinates)
曲面细分
可选的阶段
曲面细分可以为一个曲面生成数量合适的三角形,同时兼顾质量和效率。
顶点可以表示点、线、三角形,也可以来描述一个曲面(例如球体),这样的曲面可以通过几个部分组合而成,每个部分也由一组顶点构成
曲面细分阶段本身也包含一系列子阶段:
- 壳着色器(hull shader)
- 曲面细分器(tessellator)
- 域着色器(domain shader)
它们可以将当前的顶点集合转换为更大的顶点集合,从而创建出更多的三角形
相机位置可以用来决定需要生成多少个三角形:当距离相机很近时生成较多数量的三角形,当距离远时生成较少数量的三角形
几何着色器
可选的阶段
出现时间早于曲面细分着色器,所以也更简单,能够做的事情也更少
有好几种用途,最流行的是用来生成粒子
流式输出
最后一个可选阶段
这一阶段可以让我们把 GPU 作为一个几何引擎,可以选择将这些处理好的数据输入到一个缓冲区中,而不是直接输入到渲染管线的后续部分
这些缓冲区中的数据可以被 CPU 读回使用,也可以被 GPU 后续步骤使用
这个阶段通常会用于粒子模拟
裁剪
只有完全位于标准视空间内部,或者部分位于内部的图元,才需要被发送给光栅化阶段
完全位于内部的图元被原样传递,完全位于外部的图元被直接丢弃,部分位于内部的图元需要进行裁剪操作,如图所示:
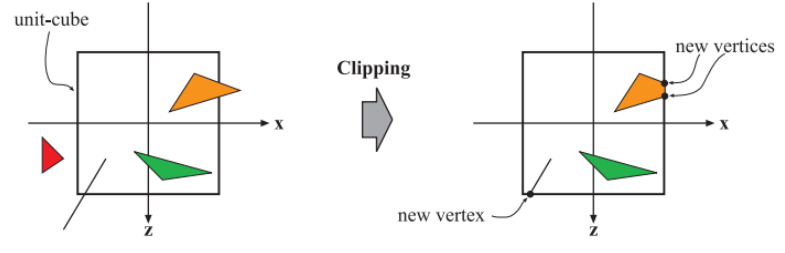
除了标准视空间的六个裁剪平面之外,用户还可以定义额外的裁剪平面进行裁剪,这种操作被称为切片(sectioning)
透视除法、三维标准化设备坐标系(normalized device coordinates,NDC)
几何处理阶段的最后一步就是将这个空间转换为窗口坐标系
屏幕映射
在标准视空间内部的图元被传递到屏幕映射(screen mapping)阶段,然后,$x$ 坐标和 $y$ 坐标会被转换为屏幕坐标(screen coordinate),屏幕坐标和 $z$ 坐标一起,被称为窗口坐标(window coordinate)
不同 API 在竖直方向上的方向可能不同
光栅化阶段
现在有了被正确变换和正确投影的顶点数据,这个阶段的目标是找到位于待渲染图元中的所有像素值
可以划分为两个子阶段:三角形设置(triangle set up,也叫图元装配,primitive assembly)、三角形遍历(triangle traversal)
注意这两个阶段同样适用于点和线,只是三角形更常见,所以名字中带有“三角形”
光栅化也被称为扫描变换(scan conversion)
判断某个三角形和屏幕上的哪些像素重合,取决于我们如何实现 GPU 管线,例如点采样(point sample,中心点在三角形内)、超采样(supersampling)、多重采样抗锯齿技术(multisampling antialiasing)或保守光栅化(conservative rasterization,像素一部分与三角形重叠)
这两个阶段使用专门的硬件单元进行执行
三角形设置
三角形的微分(differential)、边界方程(edge equation)和其他数据会在这个阶段进行计算
这些数据可以用于三角形遍历,以及对几何阶段产生的各种着色数据进行插值
这个功能一般会使用固定功能的硬件实现
三角形遍历
在这个阶段,会对每个被三角形覆盖的像素(通过某种采样方法)进行逐个检查,并生成对应的片元(fragment)
找到那些位于三⻆形内部的点或者样本,并且对三角形三个顶点上的属性进行插值,来获得每个片元的属性(深度等)
透视矫正插值(perspective-correct interpolation)
面元内部的片元会被送入像素处理阶段
像素处理阶段
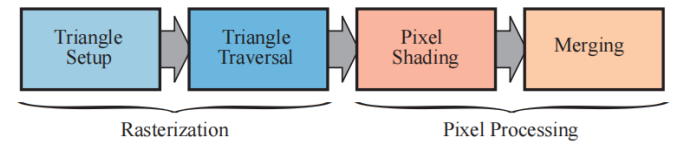
像素处理阶段可以被划分为像素着色(pixel shading)和合并(merging)两个阶段
像素处理阶段会对图元内部的像素进行逐像素的计算和操作
像素着色
这里会使用插值过的着色数据作为输入,进行逐像素的着色计算,结果是生成一个颜色值或者多个颜色值,这些颜色值会被输入到下一个阶段中
像素着色阶段由可编程的 GPU 核心来执行
所以可以使用各种各样的技术,如纹理化(texturing,将各个图像粘合在物体表面)
合并
这个阶段也叫做光栅操作管线(raster operations pipeline,ROP)或者渲染输出单元(render output unit,ROP),执行合并操作的 GPU 子单元并不是完全可编程的,但是它是高度可配置的
颜色缓冲区与深度缓冲区
像素着色阶段中,我们计算了每个片元的颜色,合并阶段负责将像素着色阶段产生的片元颜色与当前存储在颜色缓冲区(color buffer,矩形排列,存储了每个像素中的颜色信息)中的颜色相混合
合并阶段还负责解决可见性问题(当整个场景被渲染时,颜色缓冲区应当只包含这些相机可见的图元的颜色),通常通过深度缓冲(z-buffer,存储最近的片元的 $z$ 值)实现
深度缓冲这个方法不适用于透明物体的渲染,透明物体必须要等到所有不透明物体都渲染完成之后才能进行渲染,而且需要严格按照从后往前的顺序进行渲染,或者使用一个顺序无关的透明算法
在一些较老的 API 中,颜色的透明通道可以用来进行透明测试(alpha test,选择性地丢弃一些像素),但是现在丢弃像素这个操作可以在像素着色器中完成
模板缓冲区
模板缓冲区(stencil buffer)是一个离屏缓冲区(offscreen buffer),可以用来记录被渲染图元的位置信息,通常它的每个像素包含 8bit,它可以用来控制渲染到颜色缓冲区和深度缓冲区的内容
模板缓冲⼗分强大,可以用于生成一些特殊效果
所有这些在管线末尾的功能都被叫做光栅操作(raster operation)或者混合操作(blend operation)。前面提到,这些操作通常不是完全可编程的,一般只能通过 API 来进行配置。但是某些 API 支持光栅顺序视图(raster order view),也被叫做像素着色器排序,它支持可编程的混合操作
帧缓冲与双缓冲机制
系统中所有的缓冲区(应该只包含像素处理阶段的缓冲区)在一起,被统称为帧缓冲(frame buffer)
为了避免用户看到图元渲染的过程,一般会采用双缓冲机制(double buffering)
前置和后置缓冲区的交换过程发生在垂直回扫(vertical retrace)的过程中