着色的计算频率
- 只计算一次,编译阶段就能完成
- 每一帧只计算一次
- 每个 draw call 都会发生变化,则需要放在着色器中计算:
- 顶点着色器(Vertex Shader):在每个曲面细分前的顶点上进行计算
- 壳着色器(Hull Shader):在每个表面面片上进行计算
- 域着色器(Domain shader):在每个曲面细分后的顶点上进行计算
- 几何着色器(Geometry shader):在每个图元上进行计算
- 像素着色器(Pixel shader):在每个像素上进行计算
实际上,大部分着色计算都是逐像素执行的,但是使用计算着色器来实现的例子也越来越多
理论上来说,我们可以在像素着色器中只计算着色模型的高光(specular highlight)部分,并在顶点着色器中计算着色模型的剩余部分。但是实际上会带来额外的性能开销,导致弊大于利
插值:表面法向量在插值前和插值后都需要归一化,光线方向并不需要插值,只需要插值表面位置即可
也有风格化的渲染方式使用逐图元着色,通常被称作平面着色(flat shading)
材质系统
着色器是某个 GPU 可编程着色阶段中的一个程序。因此着色器是一个底层(low-level)的图形 API 资源,而不是艺术家可以直接进行交互的东西
材质(material)对表面的视觉外观进行了封装,它才是直接面向艺术家的资源
材质和着色器并不是简单的一对一的关系。在不同的渲染场景中,有时候相同的材质可能也会使用不同的着色器,一个着色器也可能会被多种材质所共享,最常见的情况就是参数化材质
材质参数化需要两种材质实体:材质模板(material template)和材质实例(material instance)
材质系统最重要的任务之一,就是将各种着色器功能划分为独立的元素,并控制这些元素的组合方式
GPU 着色器并不允许在编译后再去链接代码片段,只能在源代码阶段进行组合
尽量不使用动态分支(会产生运行时着色器变体),尽量在编译阶段就处理变体(产生编译时着色器变体),现代的材质系统会同时使用运行时着色器变体和编译时着色器变体,材质系统的设计者采用了不同的策略:
- 代码复用:在共享文件中实现可复用的函数,使用
#include - 做减法:在一个很大的着色器中,灵活使用编译时的预处理指令与动态分支的组合
- 做加法:将各种单位功能定义成具有输入输出连接器的节点,这些功能节点可以被组合在一起
- 基于模板:定义接口
材质系统还需要保证良好的性能,可以进行一些常见的优化,例如将一次 draw call 中结果为常数的计算移动到着色器之外进行
基于屏幕的抗锯齿
超采样(supersampling):对每个像素计算多个完整样本的抗锯齿方法
概念上最简单的超采样方法是全屏抗锯齿(full-scene antialiasing,FSAA),或者叫超采样抗锯齿(supersampling antialiasing ,SSAA),使用 box 滤波器。这个方法的开销很大,每个子样本都需要进行完整的着色和填充
NVIDIA 的动态超分辨率(dynamic super resolution)更加精细,使用包含 13 个样本的高斯滤波器
一些采样方案的对比:
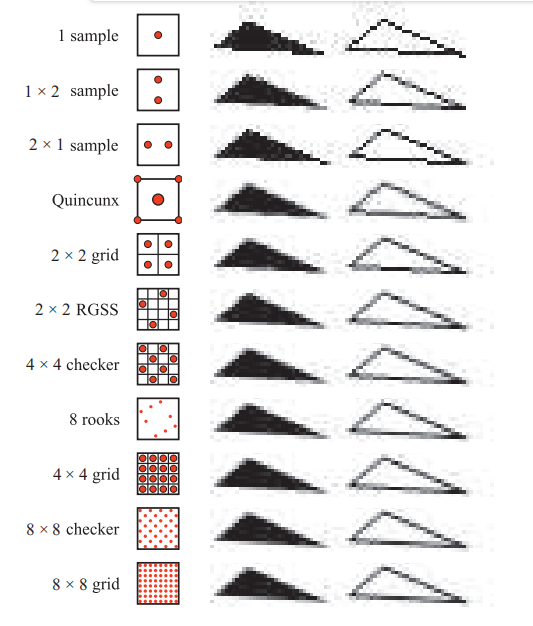
累积缓冲区(accumulation buffer)
前面的这些技术中,采样点和普通像素一样,都会独立完整地进行着色计算并维护深度信息
GPU 一些新特性打开了抗锯齿的新思路,例如保守光栅化(conservative rasterization)和光栅器有序视图(rasterizer order view)
多重采样抗锯齿(Multisampling antialiasing,MSAA):如果样本位置都被这个片元所覆盖,那么在像素的中心位置来计算这个着色样本;否则使用质心采样(centroid sampling)或叫做质心插值(centroid interpolation)的方法来得到覆盖的样本进行计算。一般使用 box 滤波器
覆盖采样抗锯齿(coverage sampling antialiasing,CSAA)
增强质量抗锯齿(enhanced quality antialiasing,EQAA):2f4x 模式,深度和颜色信息共享,样本通过索引的方式拿到它们,并且深度和颜色信息有上限,超过上限则丢弃
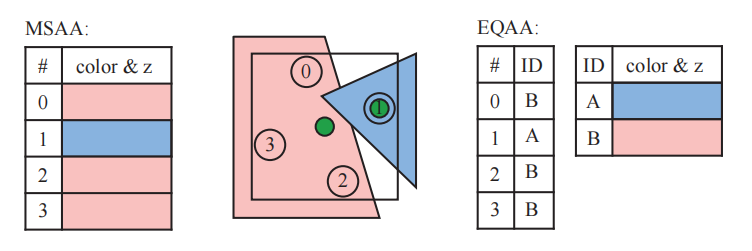
当场景中所有的几何体都被渲染到一个多样本缓冲区(multiple-sample buffer)之后,会进行一个解析(resolve)操作,会对样本的颜色进行平均化,并最终决定像素的颜色
在现代的 GPU 上,像素着色器或者计算着色器可以访问 MSAA 的样本,并使用任何我们所需要的滤波器来进行重建,甚至可以访问周围像素的样本。
时域抗锯齿(temporal antialiasing,TAA):通过之前几帧的结果来对当前帧进行优化的抗锯齿技术。与之前几帧的图像按照权重进行混合
会有一些问题,例如闪烁(shimmer)和鬼影(ghosting)
解决鬼影的方法:
- 只对缓慢移动的物体使用时域抗锯齿
- 重投影(reprojection):生成运动向量(motion vector)存在速度缓冲区(velocity buffer)中,用于找到前一帧中该表面位置所对应的像素
延迟渲染技术并不兼容 MSAA 和其他的多重采样抗锯齿技术
TXAA、多帧采样抗锯齿(multi-frame antialiasing,MFAA)都使用了时域抗锯齿
采样模式
高效的采样模式(sampling pattern)是减少瑕疵和时间开销等方面的关键因素
旋转网格超采样(rotated grid supersampling,RGSS):在水平边缘与垂直边缘的附近的锯齿,对人类的视觉影响最大,其次便是倾角接近45度的边缘。RGSS 使用了一个旋转后的正方形采样模式来进行采样
N-rooks 采样模式:$n$ 个采样点被放置在一个 $n \times n$ 的网格内,每行和每列都各有一个样本点
N-rooks 采样模式只是创建良好采样模式的基础,其本身还不够好,为了更好的进行采样,我们希望避免将两个样本放在一起。同时我们希望将这些样本均匀分布在这个像素区域中。为了获得这样的采样模式,我们可以将例如拉丁超立方体(Latin hypercube)采样的分层抽样(stratified sampling)技术与其他方法相结合,例如抖动(jittering)采样,Halton序列以及泊松圆盘采样(Poisson disk sampling)
下面是 AMD 和 NVIDIA GPU 所采用的 MSAA 采样模式(2 倍到 8 倍):
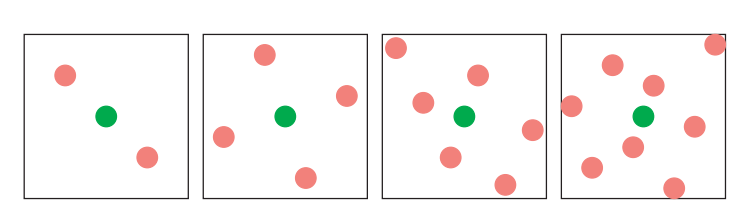
小物体(例如梳子的梳齿)走样(摩尔纹),可以采用随机采样(stochastic sampling)来防止采样模式在像素之间重复:
- 交错采样(interleaved sampling)
- 索引采样(index sampling)
- 使用交错随机采样(interleaved stochastic sampling)
五点型(Quincunx)方法,边界共享样本信息,实际上每个像素只有两个样本的较低开销,可以用于时域抗锯齿
FLIPQUAD(字面意思是翻转四边形)采样模式:
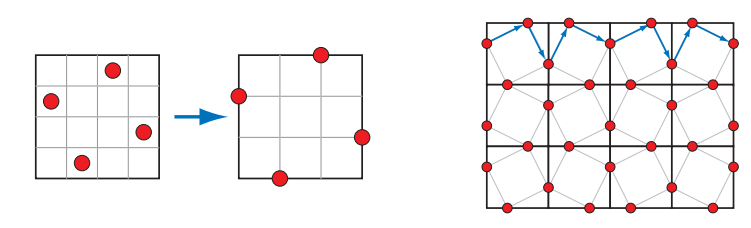
FLIPQUAD 方法也可以用于时域抗锯齿,在两帧之间共享样本
混合重建抗锯齿方法(hybrid reconstruction antialiasing,HRAA)
形态学方法
形态学抗锯齿(morphological antialiasing,MLAA):与物体的结构或者形状有关的抗锯齿方法
这种形式的抗锯齿是作为一个后处理(post-process)来执行的,这类型的技术依赖于一些额外的缓冲区(例如深度缓冲和法线缓冲)来生成更好的结果,最普通的方法只需要使用颜色缓冲
亚像素重建抗锯齿(subpixel reconstruction antialiasing ,SRAA),只适用于几何边缘的抗锯齿处理
几何缓冲区抗锯齿(geometry buffer antialiasing,GBAA)、距离边缘抗锯齿(distance-to-edge antialiasing,DEAA)
定向局部抗锯齿(directionally localized antialiasing,DLAA):接近垂直的边缘被水平模糊,接近水平的边缘与其相邻像素进行垂直模糊
仅仅使用纯颜色缓冲的算法可以很好地与渲染管线相解耦,使得它们易于修改和禁用,其中两种最流行算法分别是快速近似抗锯齿(fast approximate antialiasing,FXAA)和亚像素形态学抗锯齿(subpixel morphological antialiasing,SMAA),其中 SMAA 可以访问 MSAA 的样本
半透明渲染
在半透明渲染的算法中,最后生成的效果可以大致分为:
- 基于光线(light-based)的半透明效果:半透明物体会导致光线发生衰减和偏移,从而使得场景中的其他物体会被照亮,或者呈现出不同的渲染效果
- 基于视图(view-based)的半透明效果:透明物体自身的渲染效果
点阵剔除半透明(screen-door transparency):舍弃一部分像素。如果多个物体重叠在一起则不真实
随机透明度(stochastic transparency)
alpha 混合(alpha blending)
一个像素的 alpha 值可以用于表示不透明度,覆盖率或者同时表示这两者,具体需要依情况而定。例如 MSAA 中的样本,如果物体覆盖了四分之三的像素并且 alpha 是 0.1,那么最后这个样本的 alpha 就是 $0.75\times 0.1=0.075$
混合顺序
$\mathbf {over}$ 运算符:
$$ \vec c_o=\alpha_s\vec c_s+(1-\alpha_s)\vec c_d $$其中,$\vec c_d$ 是该像素在混合之前的颜色(目标颜色),$\vec c_s$ 是当前透明物体的颜色(源颜色)
在某些情况下,尤其是通过彩色玻璃或者彩色塑料,效果不好
叠加混合(additive blending):
$$ \vec c_o=\alpha_s\vec s+\vec c_d $$$\mathbf {under}$ 运算符:
$$ \begin{aligned} \vec c_o&=\frac{\alpha_d\vec c_d+(1-\alpha_d)\alpha_s\vec c_s}{a_o}\\ a_o&=\alpha_s(1-\alpha_d)+\alpha_d \end{aligned} $$顺序无关的透明度算法
顺序无关的透明度算法(order-independent transparency,OIT):不需要对透明物体进行排序
深度剥离(depth peeling):一种顺序无关的透明度算法,使用两个 z-buffer 和多个 pass:
- 第一个 pass 会将所有表面的 z-depth 信息记录在第一个 z-buffer 中,包括所有的透明表面
- 在第二个 pass 中,只会渲染所有的透明物体。如果一个透明物体的 z-depth 与第一个 z-buffer 中的深度值相匹配,那么我们可以知道,这个透明物体是距离相机最近的。然后:
- 将它的颜色信息(包括 alpha 通道)保存在一个单独的颜色缓冲区中
- 进行“剥离”操作:使用距离相机第二近的透明物体的 z-depth(如果存在的话)来更新第一个 z-buffer 中的对应位置
- 接下来的一系列 pass 中,会继续按照这种方式来剥离透明物体,并且使用 $\mathbf {under}$ 运算符进行混合
- 在一定数量的 pass 操作之后终止算法,然后将透明图像(透明物体的颜色缓冲区)混合到不透明图像上
深度剥离算法有好几种变体,例如 Thibieroz 给出了一种可以从后向前进行渲染的算法
尽管深度剥离算法可以有效渲染透明物体,但是这个算法的效率并不高,其他的方法:
- 双重深度剥离算法(dual depth peeling):使用桶排序
- A-buffer、覆盖掩码(coverage mask)
- 片元链表(linked list):通过 DirectX 11 中暴露的新特性如无序访问视图(UAV)和原子操作(atomic operation)实现
- k-buffer:保留前面若干个透明层,并对它们进行排序;对后续的透明层,会将多个层划分为一组,并使用加权平均的方式进行混合
- 多层 alpha 混合(multi-layer alpha blending):建立在 k-buffer 的思想上。像素同步(pixel synchronization),可以通过光栅器有序视图(DirectX 11.3)或 tile 本地存储(tile local storage,移动设备)实现
Alpha 预乘与合成
$\mathbf{over}$ 操作符也可以用于将照片或者物体的渲染图混合在一起,这个过程被称为合成(compositing)
在这种情况下,每个像素的 alpha 值会与物体的 $\rm RGB$ 值存储在一起,alpha 通道所构成的图像有时候也被称为遮片(matte),它展示了物体的轮廓形状
使用合成 $\rm RGB \alpha$ 数据的一种方式是 alpha 预乘(premultiplied alpha,也被称为关联的 alpha),它的意思是在使用这些 $\rm RGB$ 值之前,要先将它们与对应的 alpha 值相乘。在 alpha 预乘之后,会使得 over 方程变得更加高效:
$$ \vec c_o=\vec c'_s+(1-\alpha_s)\vec c_d $$渲染合成图像很适合使用预乘 alpha 的方法,因为这样我们就能把 alpha 通道的意义变成只有覆盖面积
另一种存储图像的方法是使用未相乘的 alpha(unmultiplied alpha),也被称为不关联的 alpha
在执行过滤和混合操作的时候,最好是使用 alpha 预乘的颜色数据,否则诸如线性插值的一些操作无法正确执行(?)
PNG 仅支持不关联的 alpha,OpenEXR 仅支持关联的 alpha,TIFF 同时支持两种关联类型的 alpha
色键抠像(chroma key)、绿幕
显示编码
在计算光照,纹理效果或者是其他操作的时候,我们会假设所使用的值是线性的(linear)
但是为了避免各种视觉瑕疵,显示缓冲区和纹理中使用了非线性的编码方式
伽马校正(gamma correction)
CRT(cathode-ray tube,阴极射线管)显示器中,显示 radiance 和输入电压之间具有指数关系,这种编码方式在人眼感知上大致是均匀的
纹理(非线性)被解码成线性,在着色后,最终计算出的颜色值进行了编码成了非线性,并存储在帧缓冲中。帧缓冲中的颜色值与显示转换函数(描述了显示缓冲区中的值与实际显示器发光强度之间的关系),最终决定了显示器上的发光强度。如图:
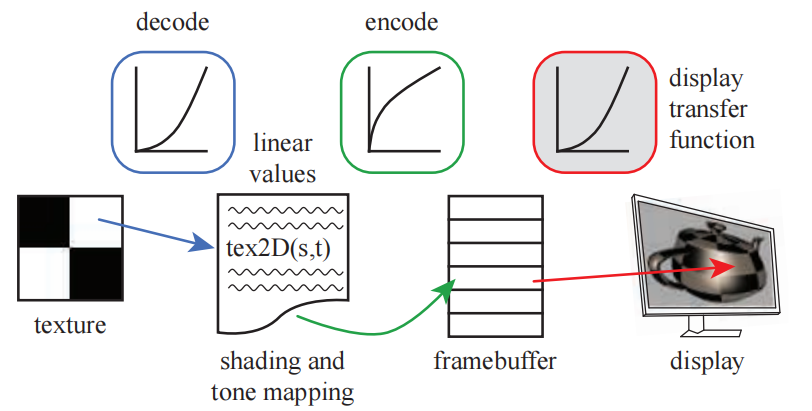
不使用伽马校正的坏处:
- 基于物理的线性 radiance 的着色计算出现错误
- 影响抗锯齿边缘的质量,扭绳(roping)